During a conversation with my colleague, he mentioned to me about a problem that he was asked in his technical interview. The problem was to find the duplicates in an array of integers. My immediate reaction – “That is easy and I am sure you got it !” But just then there was a two second silence from his end and then he said that he couldn’t get it right since some additional constraints were mentioned to him ‘later’.
Problem Statement
Find the elements which appear twice in an array of integers, where the elements in the array being : 1 ≤ a[i] ≤ n (n = size of array). We need to do this without using additional space in O(n) runtime.
Solution
Now, it was my turn to be silent for the next couple of seconds after he told me about the problem statement with the constraints about not using additional space and O(n) runtime.
We had a discussion about using a Set or may be a HashMap in Java since the main part of the problem was to find the “duplicates”. Using a Set or a Map would not be the right solution with these constraints. A nested for loop would also not be the right solution since we need to solve the problem in O(n) runtime. Well, let’s consider some sample data and try solving this step by step.
Sample Input data

The output for this input will be 10 and 1. They both appear twice. Note that the length of the array is 10 and the maximum value of any element in the array is <=10. This is an important constraint.
Let us solve this step by step

- Loop through the array and for each iteration-
- Take the value at each index. Currently at 0, in the first iteration, the value will be 10
- Subtract one from this value. During iteration 0, the result will be 9. The reason we subtract one is because the value of any element in the array is <=n, where is n is size of the array. The array index starts from 0. So an array of size 10 can contain a maximum value of 10 but there is no arr[10].
- Use this result as an index. For iteration 0, this will be 9, go to element number 9 and negate the value at this index number 9

Why should we do this and what about the duplicates ?
Well, if we encounter another value of 10 in this array, the index obtained using steps above will result in 9 again. We access to value at 9th position which is -7 now. We check if this is less than 0 and if it is less than 0, it means we have already visited the ‘value at this current iteration‘. This means it is a duplicate value. So step 3 in the algorithm above can be modified as follows:
Loop through the array and for each element in the array, let’s refer to the array as arr, do the following –
- Take the value at each iteration. Currently at 0 in the first iteration, the value will be arr[0] which is 10.
- Subtract one from this, the value will be 9. Let us refer to this value as index.
- Using this index, access the value at this index, element at index 9, arr[9]. If the value at this index is less than 0, add arr[current_iteration] to the list of duplicate elements.
- Negate the value at this index.(currently 9 for this iteration 0)
- Go back to step 1, the next iteration which is current_iteration + 1.
Flowchart


Iteration 0

Iteration 1

Iteration 2

Iteration 3

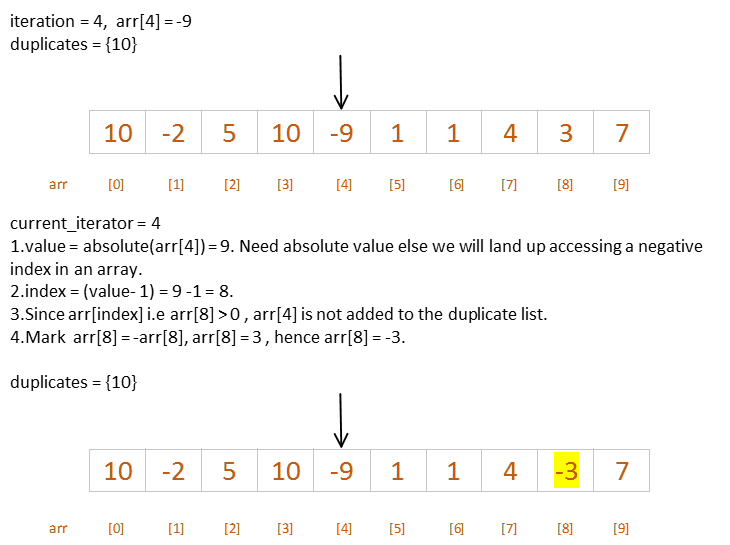
Iteration 4
In this iteration number 4, when we access the value at arr[4], we get a -9. If we were to follow step 2 of the algorithm, we would land up with an index of -10 and then in step 3 we would access arr[-10] which is incorrect. So we need to modify the algorithm to take absolute value of the same.
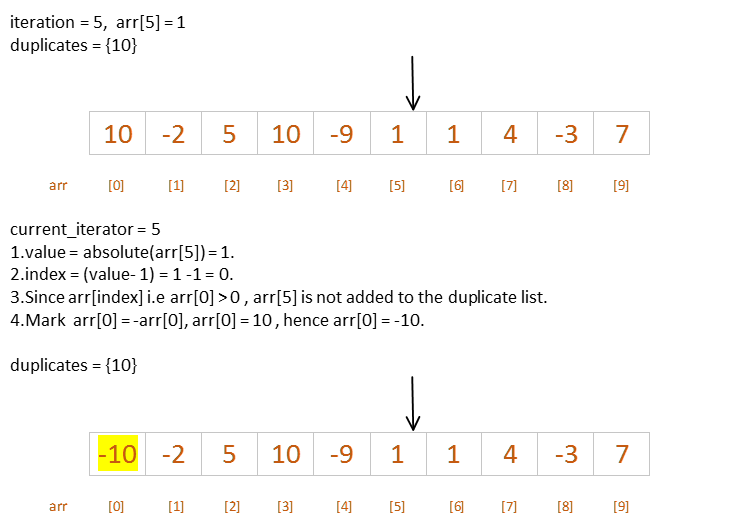
Iteration 5
Iteration 6

Iteration 7

Iteration 8

Iteration 9 (Final iteration)

Java Code
import java.util.ArrayList;
import java.util.List;
public class DuplicatesInArray {
public static List<Integer> findDuplicates(int arr[]) {
List<Integer> duplicates = new ArrayList<>();
for (int i = 0; i < arr.length; i++) {
int index = Math.abs(arr[i]) - 1;
if (arr[index] < 0){
duplicates.add(Math.abs(arr[i]));
}
arr[index] = -arr[index];
}
return duplicates;
}
public static void main(String[] args) {
int [] arr = {10,2,5,10,9,1,1,4,3,7};
List<Integer> duplicates = findDuplicates(arr);
System.out.println(duplicates);
}
}
The Math.abs is required since we could have negated the value at an index in a previous iteration. If we don’t do a Math.abs, we will land up accessing arr[-index]. For the same reason, Math.abs is also required while adding an element to the list of duplicate values.
Kotlin code
fun findDuplicates(arr:IntArray) : List<Int>{
var duplicates = arrayListOf<Int>()
for(itemIndex in arr.indices){
val goToIndex = Math.abs(arr[itemIndex]) - 1
if(arr[goToIndex] < 0 ){
duplicates.add(Math.abs(arr[itemIndex]))
}
arr[goToIndex] = -arr[goToIndex]
}
return duplicates
}
fun main(){
var arr = intArrayOf(10,2,5,10,9,1,1,4,3,7)
println(findDuplicates(arr))
}
Conclusion
We have traversed the entire array and the list of duplicates has 2 elements: 10 and 1. The flip side of this algorithm is that the elements of the array are modified but we have not used any additional storage. We have also managed to do this in O(n) as this is just a single pass of entire array.
The code in Java and Kotlin is quite simple but you need to know the algorithm/solution for this particular problem before hand. This problem is an interesting one given the constraints of space and time but I don’t think the solution was so straight forward. In my opinion, I don’t think the outcome of a technical interview should be decide based on just this problem.
