In this post, we are going to solve the problem of “valid parentheses” or “matching parentheses”. We will begin this parenthetical journey by looking at multiple examples in order to get a thorough understanding of the problem along with the solution. This will be followed by a technical analysis where all corner cases will be considered. We will then move on to write the code in Java where I will be explaining all the important parts of the code. As a final step, we will refactor the code which will make it easier to read, understand and maintain the code.
What is this problem about ?
In the matching parentheses problem, we are given an input string consisting of opening and closing brackets. The opening brackets can be any one of the following – ‘(‘ , ‘{‘ or ‘[‘ . You must have figured out the closing brackets, it could be any one of – ‘)’ , ‘}’ or ‘]’ . Given an input string with a combination of opening and closing brackets, we need to find out if the string has matching parentheses. There are 2 conditions for the input string to be valid –
- Every opening bracket must have a closing bracket of the same type.
- The opening and closing order must match.

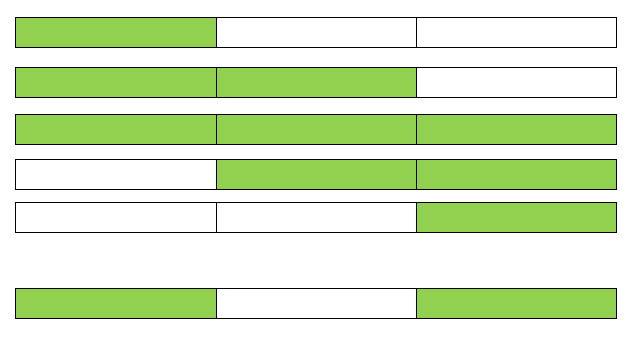
Barring the last example, the valid and invalid examples are pretty easy to spot. For the last example, the matching parentheses are shown with the same color to make it easier to understand. For the invalid one, notice the arrows,the order is not matching. Note that the spaces between the parentheses have been added only for readability.
Technical analysis
If the input string is small, it is pretty easy to match a parenthesis with your eyes irrespective of whether you look at the string from the left or the right. The moment, the strings get bigger, it becomes difficult to match them. Well, what will help you is if you start looking from the inside towards the outside. Once you start looking at the string from inside out, you are able to spot the matching ones, and then just take it virtually off from the string. Does that help you ? I think it does. I want you to remember that, it becomes easier to start from the inside, then move towards the outside and then simply knock off the matching ones so that you have fewer ones to match!
Thinking from a technical perspective
We have an input string and the output must indicate if the input is either valid or invalid. We can start writing the code with a method which takes a String as an input and returns a boolean.
public boolean isValid(String s) {
...
}
That was easy, let’s move on to the actual logic now. Every opening bracket must be matched by a closing bracket of the same type and the order must be maintained.
If the input is {}, we might think of the following – let’s begin at the first character and if the next character is a closing bracket, let’s check the previous index for an opening bracket. Well, that might work for {}, there are only 2 characters in the string. But for longer strings like {{{[]}}}, this logic could get pretty messy since there would be too many forward and backward movements in the string. Do you remember the inside out visualisation ? Well, there is no center point to start from the inside and even if we could start approximately somewhere close to the middle, we need to chop the matching brackets off. Manipulating the same input string over and over again is not a good idea either, it would not be efficient. In that case, should we copy the original string into some temporary storage ?
The input string itself is composed of an array of characters. We need some kind of a storage where we iterate through the input string and store every opening bracket until we find a closing bracket, a closing bracket of any type. Let’s consider the simplest data structure, an array. Let’s create a new array and use that to store each character until we encounter a closing bracket. If the input string is {{{[]}}}, the array could be filled up as shown below-
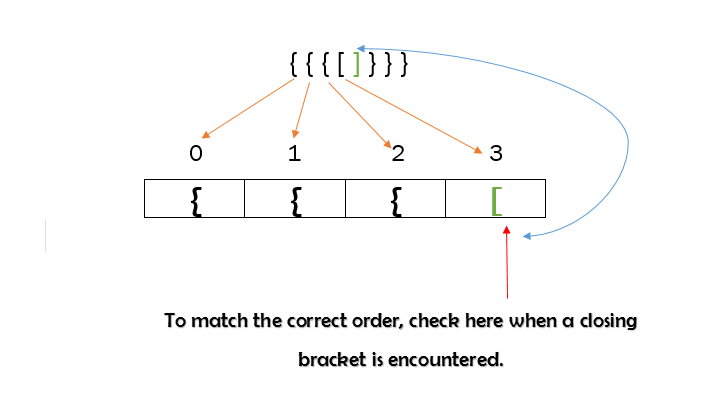
When we encounter the first closing bracket, ‘]’ , what should we do ? We need to check for a matching opening bracket , ‘[‘. It should be the latest opening bracket that was added into the array since the order has to be maintained, notice value at array[3]. This is also giving us an inside out visualization.
Should we add the closing bracket into the array as well ? Well, we don’t need to .Think about it, once we find a closing bracket in the input string, we simply match it with the opening bracket stored in the array, but with the one at the latest index. It looks like this might work, but what happens next ? We need to remove the latest item from the array once we find a matching element and adjust the index. After this step, in the input string , we might have another opening bracket(s) which needs to stored. There is going to be a lot of addition, deletion of elements, adjustment of the index in the array. Rather than implementing the array the way we just described, can we do better ? Just flip the array to the left by 90 degrees. What do you get ?
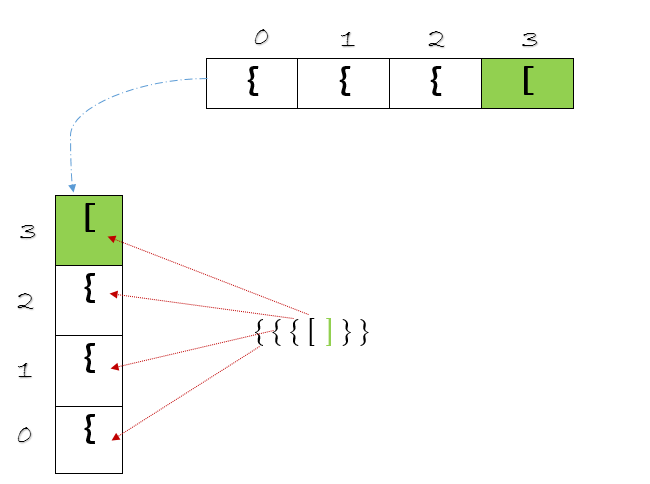
Does it look familiar ? As we iterate through the string, we are adding elements to the array. When we find a closing bracket, we want to access the topmost element in the array. Once a match is found, we want to get rid of that element.The elements also seem to be ‘stacked’ over one another. Hello,Mr.Stack !
Using the Deque interface and not the Stack class
Well, we are clearly wanting to achieve the functionality of a stack.There is a Stack class in Java and a good number of blog posts solve this problem using the Stack class. We will not be using the Stack class as it is not recommended by the creators of the Java language itself. The preferred data structure to simulate a stack like behaviour is Deque. Deque is an interface, we will use the ArrayDeque class which implements the Deque interface. Can’t we implement our own stack ? Yes, we can, but for this problem, let’s make use of the ArrayDeque class which gives us that same functionality.
Using ArrayDeque
Since we want to add elements which is the same as pushing elements, and want to remove the topmost element which is equivalent to popping an element, the Deque interface has a corresponding push and a pop method. The ArrayDeque class implements these two methods. Internally, ArrayDeque is backed by an array, a resizable array.
When do we decide if the string is valid or invalid ?
The simplest condition is when we don’t find the same type of matching bracket. If the latest opening bracket does not match the closing bracket in the string, we return false. This takes care of the order of the brackets. An example of this is : { [ } }. The inner brackets don’t match. The stack will have the topmost element as ‘[‘ but we encounter the closing bracket as ‘}’and they don’t match. When there is a mismatch between the type of brackets, we return false.
Let’s take another example now, the input string is: “{ { } ” . The first two characters are added to the stack. When we reach the 3rd character, it is a closing bracket, we pop from the stack and find a matching bracket. But we have reached the end of the string and we still have an element left on the stack, the first opening bracket, ‘{‘. What does it mean if there are elements still left on the stack when we have already iterated through the entire string ? It means that we have not been able to find a matching bracket(s). We need to handle this scenario when we still have elements on the stack but we have iterated through the entire string.This can be done using the isEmpty method on the ArrayDeque class. If there are still some element(s) left on the stack after we have iterated through the complete string, we return false.
What about the input string “{ } ]” ? The first bracket would be pushed on the stack. When we encounter the first closing bracket, we pop from the stack and check if they match. They do, we move on to the last character, ‘]’. It’s a closing bracket, we need to pop from the stack. But, wait a minute, the stack is empty! This means the closing bracket does not have a corresponding opening bracket. We found another condition, if the stack is empty when we encounter a closing bracket, we return false.
If we have not returned false from the three conditions which we have just seen, the input string is valid. What about an empty input ? Well, let’s consider an empty string or a string with just spaces in it to be a valid input.
Summary of the technical analysis
- We will be using the ArrayDeque class as a stack to push opening brackets and then pop the topmost element when we encounter a closing bracket in the input string.
- If we pop the topmost bracket from the stack and it does not match the corresponding closing bracket in the input string, we return false. This is a mismatch in the type of bracket.
- If the current input character is a closing bracket, we need to pop from the stack but if there are no elements on the stack, the stack is empty, we return false. There is a closing bracket but no corresponding opening bracket.
- If there are still some element(s) left on the stack even after complete iteration of the string, we return false. This indicates opening brackets without any closing ones.
- If the input string is an empty string, we return true.
Time for some actual code
Let’s translate the summary above into code.
Complete code
Let’s take a look at the first cut of our code.
public class ValidParentheses {
public boolean isValid(String s) {
if (null == s || s.trim().equals("")) {
return true;
}
if (s.length() % 2 != 0) {
return false;
}
int length = s.length();
Deque<Character> stack = new ArrayDeque<>(length);
for (int i = 0; i < length; i++) {
if (s.charAt(i) == '(' || s.charAt(i) == '[' || s.charAt(i) == '{') {
stack.push(s.charAt(i));
} else {
if (stack.isEmpty()) {
return false;
}
switch (s.charAt(i)) {
case ')':
if (stack.pop() != '(') {
return false;
}
break;
case ']':
if (stack.pop() != '[') {
return false;
}
break;
case '}':
if (stack.pop() != '{') {
return false;
}
break;
}
}
}
return stack.isEmpty();
}
}
- Lines 5-7 check for an empty string and return true if the input is an empty string.
- Lines 9- 11 check if the string is of odd length, if it is , we return false since it means we have an extra bracket in the string without a match. This early check can save us space and time for the code to execute.
- Line 15 creates a deque(as a stack) with appropriate length. In the worst case, we will have all open brackets which will be pushed into the stack.
- Lines 18-20 check if the character under consideration is an opening bracket, and if it is one, it is pushed into the stack.
- If the character under consideration is not an opening bracket, it must be a closing bracket. Lines 20 -23 check if the stack is empty, it should not be empty since there should be an opening bracket on the stack.
- Line 24- 42 check if the brackets are matching. Matching is done between the appropriate pairs, ‘(‘ and ‘)’ , ‘[‘ and ‘]’ and finally between ‘{‘ and ‘}’.
- Finally, line 46 checks if the stack is empty. At this point, the stack must be empty since we have iterated through the entire string. If it is not, we have extra brackets which do not have any match.
We have discussed all the scenarios earlier, you can refer to the summary section of technical analysis. The code above works but it is a little bit raw, there is definitely room for refactoring the code. Some of the code can be extracted into private functions and we can also modify the code to use the new ‘switch’ construct.
Complete refactored code
package ds;
import java.util.ArrayDeque;
import java.util.Deque;
public class ValidParentheses {
public boolean isValid(String s) {
if (isEmptyString(s)) {
return true;
}
if (isOddLength(s)) {
return false;
}
int length = s.length();
Deque<Character> stack = new ArrayDeque<>(length);
for (int i = 0; i < length; i++) {
if (isOpenBracket(s.charAt(i))) {
stack.addFirst(s.charAt(i));
} else if (stack.isEmpty()) {
return false;
} else {
boolean isMatchingClosingBrace = isValidClosingBracket(stack, s.charAt(i));
if (!isMatchingClosingBrace) {
return false;
}
}
}
return stack.isEmpty();
}
private boolean isValidClosingBracket(Deque<Character> stack, char c) {
return switch (c) {
case ')' -> (stack.removeFirst() != '(') ? Boolean.FALSE : Boolean.TRUE;
case ']' -> (stack.removeFirst() != '[') ? Boolean.FALSE : Boolean.TRUE;
case '}' -> (stack.removeFirst() != '{') ? Boolean.FALSE : Boolean.TRUE;
default -> throw new IllegalStateException("Unexpected value: " + c);
};
}
private static boolean isOpenBracket(char c) {
return (c == '(' || c == '[' || c == '{');
}
private static boolean isEmptyString(String input) {
return (null == input || input.trim().equals(""));
}
private static boolean isOddLength(String input) {
return input.length() % 2 != 0;
}
}
In case you want to read more about the new switch construct which was introduced in Java 14, I have a post which introduces you to the same.
Conclusion
This problem of parentheses matching must be solved in many computing applications. One such application is in compiler construction, where the compiler needs to determine how the different kinds of parentheses match up with each other in the source code.
The overall code is simple. It was quite important to identify and understand the usage of a stack to solve this problem. Once we realized that the stack is the appropriate data structure, it was important to use the ArrayDeque class to implement the functionality of the stack. Towards the end, we refactored the code which is something you should always strive for. Start refactoring once you have the basic working code. Clean code plays a very vital role in the long run !