In this blog we are going to solve the problem of finding the longest common substring between two strings. Guided with examples, we will begin by getting a thorough understanding of the problem and the solution. We will then look at the approach theoretically and finally we will move on to write the code in Java. Like always, I will be explaining each line of the code so that you get a good understanding of not just the ‘how’ sections of the code but also the ‘why’ sections of the code.
What is the longest common substring ?
We are given two strings as input and we need to find the longest common substring between them. What does longest common substring really mean ? Let’s break the problem down, let’s understand the meaning of each word in ‘longest common substring’.
A substring is a part of another string. A common substring is a part of the string that occurs in both the strings. Longest common substring is not just a part of string that occurs in the two strings but also has the biggest length. Let’s look at some examples to understand this better.
Examples of longest common substring
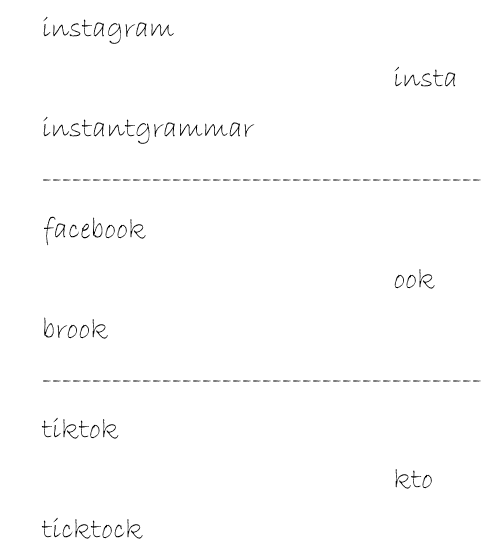
- In the first example, the input is “instagram” and “instantgrammar”. There are many common substrings like “i”, “in”, “sta”, “ram”, “gra” and a few more but the longest is “insta” or “gram” which has a length of 4.
- The input in the second example is “facebook” and “brook”. It might seem like “book” is present in both strings but note that it does not occur as a continuous string and hence not considered as a valid outcome. The right solution is “ook” .
- Finally, when the input is “tiktok” and “ticktock”, there is a “ti” , “to” and “kt” common to them which have a length of two. There are substrings with the single matching characters as well. But the longest common substring is “kto” which occurs right in the middle of the two strings.
Now that we have understood the problem, the solution, and the meaning of the words, longest common substring, let’s go ahead and understand the technique that we will use to solve this problem.
Technique applied to arrive at the solution
Brute force ?
If we are given 2 strings as input, we need to find the longest common substring. When we think of a substring, the immediate solution that comes to mind is comparing the strings. What might seem like a simple approach to arrive at the solution is probably the following-
- We start by comparing first character from the first string with every character in the second string.
- If they are equal at some point, we will then have to compare the next character from the first string and look at the next character in the 2nd string and check for equality.
- At the end of step 1, if we don’t find a matching character in the second string, we will move to the next character in the first string, start comparing it with every character in the second string and repeat the same procedure.
- Between all these comparisons, if are able to find a common substring, we will also have to maintain the length of each one. This will enable us to find the length of the longest common substring.
This approach might seem simple but this brute force solution seems to be systematically listing all the possible candidates or combinations for the solution and keeps checking if it satisfies the condition of the solution. Let’s take a look at a better solution.
Using a table or a matrix to store results
What is clear is that we need to compare the characters in each string and find a matching substring that has the biggest length.
At any given point or index in the strings, if the characters are equal, what will be the length of the common substring at that index ? If we were to represent current characters under comparison with indices i and j, and the characters are equal, the length of the longest common substring will be the length calculated upto the index, plus one.

When the characters are equal as shown using red arrow on top half of the image,what is the length of the substring at that point ? It will be the length of the common substring before that, plus one. So for this particular string, it will be one, it is the first common string since we have found nothing common at the previous index.
Similarly, in the bottom half the image, the length of the common string will become one plus the previous value. In this case, it will be 2. So we could generalize this a little bit and say that- At any given index, i , j of two strings, if the two characters at i and j are equal, the length of the common substring will be length at ( i – 1, j – 1 ) + 1 .
What we have done by deducing this is actually solved a subproblem. We are able to find the length at a particular index, which is a part of the main problem. What we are also doing is making use of the results from the previous index which is the previous subproblem. This technique is called dynamic programming.
During every comparison , we need to store the length at the appropriate indices. We have 2 indices, i and j. Let’s try and represent the 2 strings using a 2-dimensional matrix as shown below.
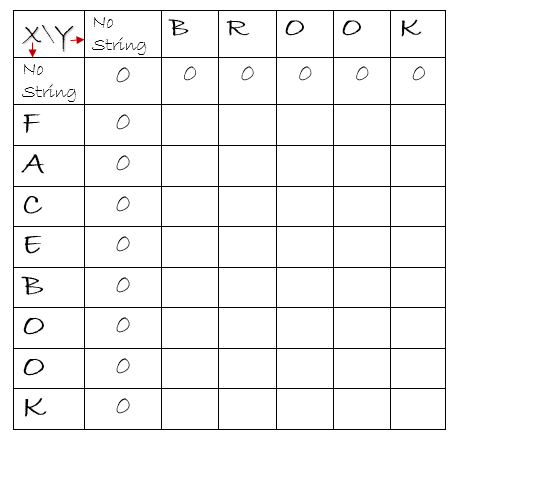
If we are given 2 strings, x and y as “facebook” and “brook”, respectively, we could represent it as shown above. This is a row,column format where a particular [row, column] combination represents a character each from the two inputs strings. The extra row and column represents a case when the input string is empty. The 0 in that row and column will represent that the length of common substring is zero when one of the the strings is empty.
How to make use of this representation?
We start comparing the characters in the two strings. If they are not equal,we enter a 0. What if they are equal ? Do you remember the generalized case ? If they are equal, at any index, [ i , j ] , the length will be [i – 1, j – 1] + 1. What is the cell [i -1 , j – 1] ? If ‘i’ represents the row and ‘j’ the column, it means the value at the previous row and previous column, it is the diagonal. Let’s take a look-

If we are at i = 2 and j = 1, [2,1] , it represents the 3rd character in first string and 1st character in 2nd string. If they are equal, we need to get the length of [i -1 , j -1 ]. So, reducing the row and column value by 1 in [ 2 , 1 ] gives us [ 1, 0] which is the diagonal element. We add one to the value at diagonal element and store it at that cell. This will indicate that we have found another continuous matching character and the length is 1 more than the length of the previous substring.
With this representation in place, we need to fill this table up with values corresponding to the comparison. The logic during this comparison will be:
- If the characters are equal, add 1 to the value at the diagonal and store the value at cell under consideration.
- If they are unequal, enter 0 at that cell.
With this 2 step procedure, the strings “facebook” and “brook” can be represented as follows-

We start by comparing the character ‘F’ in “FACEBOOK” with every character in the string “BROOK”. If there is a match, we add one to the value at diagonal and enter this value at corresponding cell. If they are unequal, we simply enter 0 in that cell.
As you can see, we have a few substrings. To track some of them, simply look at the cell with a value greater than or equal to one. Some of the substrings are “B”,”O”. A substring of length 2 indicates the substring “OO” after we match the 2nd ‘O’.
Finally, we can see a substring of length 3. We got this value because of a matching “OO” before the matching “K”. The value at this cell is obtained by adding 1 to the value at diagonal element which has value 2. We have reached the end of the strings.
Tracking the longest common substring
We made use of a two dimensional table and filled each cell with the length at a particular index, [ i , j ], of the 2 strings. When we reached the end, we were able to calculate the length of the longest common substring. That is definitely what we need, but in addition to that, we also need to know what the substring is. Let’s revisit our table with some additional information.

The table above shows row and column values as well. Can we make use of the row and column values to track the string “OOK” ? We have found the maximum length, 3, which is shown at the bottom right corner. What row and column does it belong to ? It belongs to [8 , 5]. Mapping this row number 8 to the 8th character in the string,”FACEBOOK”, which character do you see at that position ? The letter at that position is K. This can be accessed as character number 8 of the string, “FACEBOOK“. We got our first character! What do we do next ?
We travel the diagonal which is reducing the row number by a value of 1, this gives us 7. Let’s access character number 7 in the string “FACEBOOK”. It is the character ‘O’, we append it to the previous letter, ‘K’. This gives us KO.We got our 2nd character. Taking the next diagonal element gives us row number 6. Accessing character number 6 in the string “FACEBOOK” give us ‘O’. So far, we have “KOO”, 3 characters. We should stop now since the maximum length is 3 and we extracted 3 characters from the table and created a substring out of it. We simply reverse the substring, “KOO” to get “OOK”. We have got our desired result !
An important thing to remember is that in order to get the actual substring, we start the journey along the diagonal from the point that we have found the maximum length. This could be at the end of the string,in the middle or at the beginning. So it’s important to keep track of the maximum length. Let’s look at another example to solidify our understanding.

If the 2 strings are “tiktok” and “ticktock”, the largest common substring is “kto” as shown above. We start tracking the string from the maximum length,which is 3. We access the character at that particular index and take the path of the diagonal three times since the maximum length is 3. That gives us the longest common substring. Having understood the theory with these examples, I think it is time to summarize what we have done so far and move on to the code.
Summary of the technique
- We used a table, a 2 dimensional table to represent the two strings. Each cell in this table helped us in representing the length of the common substring at a given point. This gave us a nice { row , column } pair.
- We compared each character in the first string with all the characters in the 2nd and filled up each cell in the table with appropriate length-
- If they were equal, value was calculated as 1 + [value at diagonal]. Cell at diagonal is [ i – 1 , j – 1 ].
- If unequal, value was 0.
- We kept track of the maximum length as we progressively filled up the table.
- Once we reached the end of table or the string, we picked this maximum value and started travelling across the diagonal since that gave us the longest common substring.
I think we have gone through a lot of theory, we need to get technical now, let’s translate this summary into code.
Step by step analysis of the code

We need a table or matrix to represent the length at each point [i , j] of the strings. How do we represent a matrix like this ? We need to also store the length up to a certain index, [ i , j ]. The strings are of fixed length. We can do this with an array, a 2-d array. Let’s call that array, lcsTable. An array has a size.What should be the size of the 2-d array ? One thing to note is that we have 1 additional row and column filled with zeros to indicate the absence of one of the strings. The number of rows can be the size of the first string and number of columns is the size of the 2nd string. Let’s represent the length of the first and second string with ‘m’ and ‘n’ respectively. Now, our 2-d array can be initialized as follows-
private static void lcs(String x, String y) {
int m = x.length();
int n = y.length();
//to compensate for additional row and column with 0
int[][] lcsTable = new int[m + 1][n + 1];
}
The first row and the first column needs to be filled up with zeros. So we require two ‘for’ loops which accesses lcsTable[i][0] and lcsTable[0][j] and assigns them to 0. The first loop keeps column constant and changes row number and 2nd one keeps row constant and changes column number. The code for this will be-

// init first column with 0
for (int i = 0; i < m; i++) {
lcsTable[i][0] = 0;
}
// init first row with 0
for (int j = 0; j < n; j++) {
lcsTable[0][j] = 0;
}
Logic for actual comparisons
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (x.charAt(i - 1) == y.charAt(j - 1)) {
lcsTable[i][j] = 1 + lcsTable[i - 1][j - 1];
if (maxLength < lcsTable[i][j]) {
maxLength = lcsTable[i][j];
maxRow = i;
maxColumn = j;
}
} else {
lcsTable[i][j] = 0;
}
}
}
- At lines 1 and 2, we have a nested for loop. The index ‘i’ iterates through the characters in the first string, x, and ‘j’ iterates through string ‘y’. So each character in the string ‘x’ is compared with the characters in string ‘y’. We have started from index 1 since we have row 0 and column 0 to represent a condition where one input string is empty/missing.
- Line 3 checks if the characters are equal. An ‘i-1’ and ‘j-1’ is required since first character in a string begins at index 0 but loop starts from index 1. If they are equal , we access the diagonal cell which is [ i-1, j -1] and add 1 to it.
- The variable, maxLength, is required as we need to know the maximum length which can be anywhere in the table and not necessarily at the end.
- We have also introduced 2 new variables, ‘maxRow’ and ‘maxColumn’. This will point to the actual cell where the maximum length of substring was found. We will then use these variables to access the substring as shown in the previous examples.

Code for retrieving the longest common substring
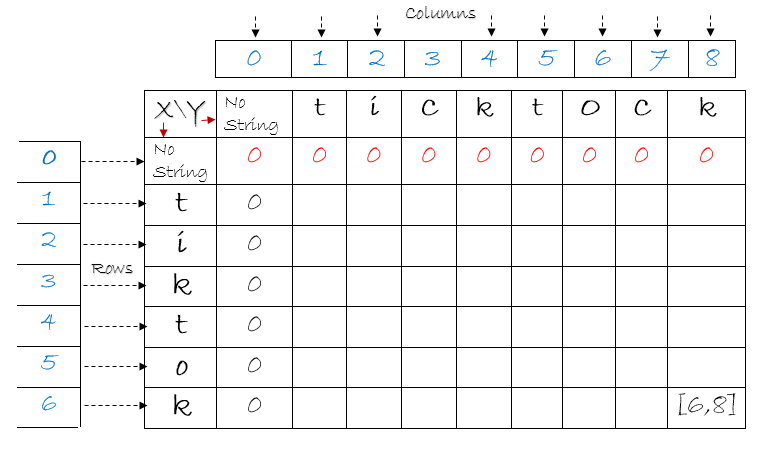
Once the table is filled and we have completed all iterations, the maximum length is in place. We need to find the actual string. We can use the variables, ‘maxRow’ and ‘maxLength’ for this. When our strings were “tiktok” and “ticktock”, we can see that the value of ‘maxRow’ is 5 and ‘maxLength’ is 3.

As you can see above , value at cell [ 5 , 6 ] is 3. The row value in [ 5 ,6 ] is 5. If you refer to the string, ‘X’ which is “tiktok” and access 5th character, we get ‘o’. You could consider using the variable,’maxColumn’. In that case the string we must use is “ticktock”. We extract the characters three times since the maximum length that has been found is 3. The code for this will be:
StringBuilder longestCommonSubstring = new StringBuilder(maxLength);
while (maxLength > 0) {
longestCommonSubstring.append(x.charAt(maxRow - 1));
maxRow--;
maxLength--;
}
Finally, don’t forget to reverse the string ! Note that we access the character in the input string by reducing 1 from maxRow. Remember that we have 1 additional row and column and strings begin at index 0.
Putting all the snippets of code together
package ds;
public class LongestCommonSubstring {
public static String findLCS(String x, String y) {
int m = x.length();
int n = y.length();
//to compensate for additional row and column with 0
int[][] lcsTable = new int[m + 1][n + 1];
// to find the maximum length
int maxLength = 0;
int maxRow = 0;
int maxColumn = 0;
// init first row with 0
for (int i = 0; i < m; i++) {
lcsTable[i][0] = 0;
}
// init first col with 0
for (int j = 0; j < n; j++) {
lcsTable[0][j] = 0;
}
// starting from 1 as row 0 and col 0 filled with 0. <= since it has go up to string length.
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (x.charAt(i - 1) == y.charAt(j - 1)) {
lcsTable[i][j] = 1 + lcsTable[i - 1][j - 1];
if (maxLength < lcsTable[i][j]) {
maxLength = lcsTable[i][j];
maxRow = i;
maxColumn = j;
}
} else {
lcsTable[i][j] = 0;
}
}
}
return fetchLCS(x, maxLength, maxRow, maxColumn);
}
private static String fetchLCS(String x, int maxLength, int maxRow, int maxColumn) {
System.out.println("The length of longest common substring is: " + maxLength);
System.out.println("Max Row is: " + maxRow);
System.out.println("Max Column is: " + maxColumn);
StringBuilder longestCommonSubstring = new StringBuilder(maxLength);
while (maxLength > 0) {
longestCommonSubstring.append(x.charAt(maxRow - 1));
maxRow--;
maxLength--;
}
return longestCommonSubstring.reverse().toString();
}
public static void main(String[] args) {
String x = "tiktok";
String y = "ticktock";
String longestCommonSubstring = findLCS(x, y);
System.out.println("The longest common substring is " + longestCommonSubstring);
}
}
Conclusion
We solved the problem of finding the longest common substring by solving the subproblem at a given index where we made use of the earlier results stored in a table. This is the essence of dynamic programming and it is a very effective technique to solve these types of problems. This technique is much better and it is a very good solution as compared to the brute force technique which we saw at the beginning. The time complexity using the dynamic technique approach is O(m*n), m and n are the lengths of the 2 strings.
Can we improve this any further ? Yes, we can! Using a suffix tree we can improve this solution even further but I think the solution using suffix trees deserves to be in another blog.

One thought on “How to find the longest common substring in Java?”