Java 9 was released in September 2017. Six months later came Java 10. Since then, a new version of Java gets released every six months. The latest version is Java 17, released in September 2021, this year.
The Java platform is evolving at a rapid pace. With every release, we get several updates and capabilities provided by the Java language and the platform. These changes can have a solid impact on our productivity and the performance of our application.
New Course on Udemy – Thinking Beyond Java 8
So in case you are a Java developer wanting to catch up with the ever-evolving Java language and platform or wish to learn the new features of modern Java, I just released my second course on Udemy that will help you do the same.
In this course, we begin our journey from Java 9 and move step by step through every release up to Java 17 and discover:
Language Features
Changes in the String class, Stream API
Garbage collectors like G1, ZGC, Epsilon, Shenandoah
Productivity tools like JShell, Java Flight Recorder, and more
Java Microbenchmark Harness
Performance-related improvements
Removals & deprecations
Modularity, jdeps, jlink, jdeprscan and
Much more!
Want to know more about the course?
Check out the course landing page and the preview videos to learn more about the course.
Prerequisites
The only prerequisite is that you have some programming experience with Java 8 since some code examples contain Lambdas and Streams code. Besides this, we use Maven only for a handful of lectures.
I have just launched my first course on Udemy. The course is on Lambdas and Streams in Java.
It is a comprehensive course(18 hours) where I start from the basics and dive deep into Lambda Expressions and the Stream API.
I also cover several features introduced in Java 8 like default methods, Method References, the Optional API, Comparators, Collectors, flatMap, Parallel Streams, and many more concepts. Besides this, there are plenty of exercises (along with the solutions).
The entire first section is available for preview. You can find more details and enroll in the course by clicking on the following link –
In this post, we are going to solve the problem of “valid parentheses” or “matching parentheses”. We will begin this parenthetical journey by looking at multiple examples in order to get a thorough understanding of the problem along with the solution. This will be followed by a technical analysis where all corner cases will be considered. We will then move on to write the code in Java where I will be explaining all the important parts of the code. As a final step, we will refactor the code which will make it easier to read, understand and maintain the code.
What is this problem about ?
In the matching parentheses problem, we are given an input string consisting of opening and closing brackets. The opening brackets can be any one of the following – ‘(‘ , ‘{‘ or ‘[‘ . You must have figured out the closing brackets, it could be any one of – ‘)’ , ‘}’ or ‘]’ . Given an input string with a combination of opening and closing brackets, we need to find out if the string has matching parentheses. There are 2 conditions for the input string to be valid –
Every opening bracket must have a closing bracket of the same type.
The opening and closing order must match.
Valid and invalid examples of matching parentheses
Barring the last example, the valid and invalid examples are pretty easy to spot. For the last example, the matching parentheses are shown with the same color to make it easier to understand. For the invalid one, notice the arrows,the order is not matching. Note that the spaces between the parentheses have been added only for readability.
Technical analysis
If the input string is small, it is pretty easy to match a parenthesis with your eyes irrespective of whether you look at the string from the left or the right. The moment, the strings get bigger, it becomes difficult to match them. Well, what will help you is if you start looking from the inside towards the outside. Once you start looking at the string from inside out, you are able to spot the matching ones, and then just take it virtually off from the string. Does that help you ? I think it does. I want you to remember that, it becomes easier to start from the inside, then move towards the outside and then simply knock off the matching ones so that you have fewer ones to match!
Thinking from a technical perspective
We have an input string and the output must indicate if the input is either valid or invalid. We can start writing the code with a method which takes a String as an input and returns a boolean.
public boolean isValid(String s) {
...
}
That was easy, let’s move on to the actual logic now. Every opening bracket must be matched by a closing bracket of the same type and the order must be maintained.
If the input is {}, we might think of the following – let’s begin at the first character and if the next character is a closing bracket, let’s check the previous index for an opening bracket. Well, that might work for {}, there are only 2 characters in the string. But for longer strings like {{{[]}}}, this logic could get pretty messy since there would be too many forward and backward movements in the string. Do you remember the inside out visualisation ? Well, there is no center point to start from the inside and even if we could start approximately somewhere close to the middle, we need to chop the matching brackets off. Manipulating the same input string over and over again is not a good idea either, it would not be efficient. In that case, should we copy the original string into some temporary storage ?
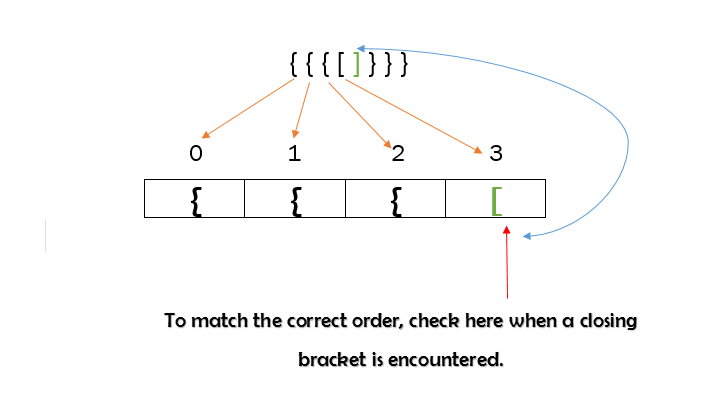
The input string itself is composed of an array of characters. We need some kind of a storage where we iterate through the input string and store every opening bracket until we find a closing bracket, a closing bracket of any type. Let’s consider the simplest data structure, an array. Let’s create a new array and use that to store each character until we encounter a closing bracket. If the input string is {{{[]}}}, the array could be filled up as shown below-
Using an array to find matching brackets
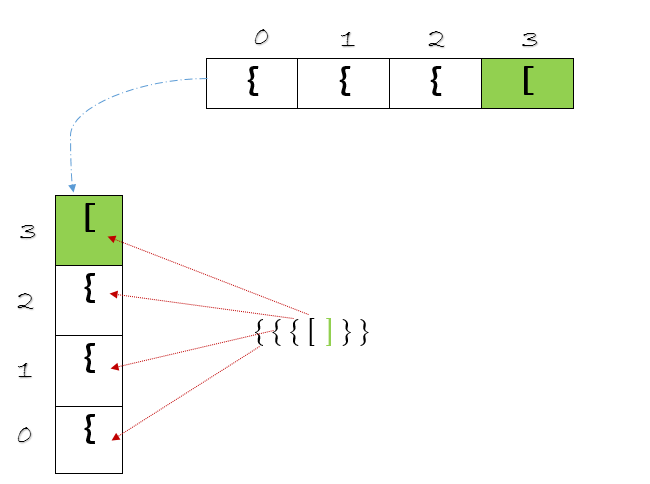
When we encounter the first closing bracket, ‘]’ , what should we do ? We need to check for a matching opening bracket , ‘[‘. It should be the latest opening bracket that was added into the array since the order has to be maintained, notice value at array[3]. This is also giving us an inside out visualization.
Should we add the closing bracket into the array as well ? Well, we don’t need to .Think about it, once we find a closing bracket in the input string, we simply match it with the opening bracket stored in the array, but with the one at the latest index. It looks like this might work, but what happens next ? We need to remove the latest item from the array once we find a matching element and adjust the index. After this step, in the input string , we might have another opening bracket(s) which needs to stored. There is going to be a lot of addition, deletion of elements, adjustment of the index in the array. Rather than implementing the array the way we just described, can we do better ? Just flip the array to the left by 90 degrees. What do you get ?
Does this data structure look familiar ?
Does it look familiar ? As we iterate through the string, we are adding elements to the array. When we find a closing bracket, we want to access the topmost element in the array. Once a match is found, we want to get rid of that element.The elements also seem to be ‘stacked’ over one another. Hello,Mr.Stack !
Using the Deque interface and not the Stack class
Well, we are clearly wanting to achieve the functionality of a stack.There is a Stack class in Java and a good number of blog posts solve this problem using the Stack class. We will not be using the Stack class as it is not recommended by the creators of the Java language itself. The preferred data structure to simulate a stack like behaviour is Deque. Deque is an interface, we will use the ArrayDeque class which implements the Deque interface. Can’t we implement our own stack ? Yes, we can, but for this problem, let’s make use of the ArrayDeque class which gives us that same functionality.
Using ArrayDeque
Since we want to add elements which is the same as pushing elements, and want to remove the topmost element which is equivalent to popping an element, the Deque interface has a corresponding push and a pop method. The ArrayDeque class implements these two methods. Internally, ArrayDeque is backed by an array, a resizable array.
When do we decide if the string is valid or invalid ?
The simplest condition is when we don’t find the same type of matching bracket. If the latest opening bracket does not match the closing bracket in the string, we return false. This takes care of the order of the brackets. An example of this is : { [} }. The inner brackets don’t match. The stack will have the topmost element as ‘[‘ but we encounter the closing bracket as ‘}’and they don’t match. When there is a mismatch between the type of brackets, we return false.
Let’s take another example now, the input string is: “{ { } ” . The first two characters are added to the stack. When we reach the 3rd character, it is a closing bracket, we pop from the stack and find a matching bracket. But we have reached the end of the string and we still have an element left on the stack, the first opening bracket, ‘{‘. What does it mean if there are elements still left on the stack when we have already iterated through the entire string ? It means that we have not been able to find a matching bracket(s). We need to handle this scenario when we still have elements on the stack but we have iterated through the entire string.This can be done using the isEmpty method on the ArrayDeque class. If there are still some element(s) left on the stack after we have iterated through the complete string, we return false.
What about the input string “{ } ]” ? The first bracket would be pushed on the stack. When we encounter the first closing bracket, we pop from the stack and check if they match. They do, we move on to the last character, ‘]’. It’s a closing bracket, we need to pop from the stack. But, wait a minute, the stack is empty! This means the closing bracket does not have a corresponding opening bracket. We found another condition, if the stack is empty when we encounter a closing bracket, we return false.
If we have not returned false from the three conditions which we have just seen, the input string is valid. What about an empty input ? Well, let’s consider an empty string or a string with just spaces in it to be a valid input.
Summary of the technical analysis
We will be using the ArrayDeque class as a stack to push opening brackets and then pop the topmost element when we encounter a closing bracket in the input string.
If we pop the topmost bracket from the stack and it does not match the corresponding closing bracket in the input string, we return false. This is a mismatch in the type of bracket.
If the current input character is a closing bracket, we need to pop from the stack but if there are no elements on the stack, the stack is empty, we return false. There is a closing bracket but no corresponding opening bracket.
If there are still some element(s) left on the stack even after complete iteration of the string, we return false. This indicates opening brackets without any closing ones.
If the input string is an empty string, we return true.
Time for some actual code
Let’s translate the summary above into code.
Complete code
Let’s take a look at the first cut of our code.
public class ValidParentheses {
public boolean isValid(String s) {
if (null == s || s.trim().equals("")) {
return true;
}
if (s.length() % 2 != 0) {
return false;
}
int length = s.length();
Deque<Character> stack = new ArrayDeque<>(length);
for (int i = 0; i < length; i++) {
if (s.charAt(i) == '(' || s.charAt(i) == '[' || s.charAt(i) == '{') {
stack.push(s.charAt(i));
} else {
if (stack.isEmpty()) {
return false;
}
switch (s.charAt(i)) {
case ')':
if (stack.pop() != '(') {
return false;
}
break;
case ']':
if (stack.pop() != '[') {
return false;
}
break;
case '}':
if (stack.pop() != '{') {
return false;
}
break;
}
}
}
return stack.isEmpty();
}
}
Lines 5-7 check for an empty string and return true if the input is an empty string.
Lines 9- 11 check if the string is of odd length, if it is , we return false since it means we have an extra bracket in the string without a match. This early check can save us space and time for the code to execute.
Line 15 creates a deque(as a stack) with appropriate length. In the worst case, we will have all open brackets which will be pushed into the stack.
Lines 18-20 check if the character under consideration is an opening bracket, and if it is one, it is pushed into the stack.
If the character under consideration is not an opening bracket, it must be a closing bracket. Lines 20 -23 check if the stack is empty, it should not be empty since there should be an opening bracket on the stack.
Line 24- 42 check if the brackets are matching. Matching is done between the appropriate pairs, ‘(‘ and ‘)’ , ‘[‘ and ‘]’ and finally between ‘{‘ and ‘}’.
Finally, line 46 checks if the stack is empty. At this point, the stack must be empty since we have iterated through the entire string. If it is not, we have extra brackets which do not have any match.
We have discussed all the scenarios earlier, you can refer to the summary section of technical analysis. The code above works but it is a little bit raw, there is definitely room for refactoring the code. Some of the code can be extracted into private functions and we can also modify the code to use the new ‘switch’ construct.
Complete refactored code
package ds;
import java.util.ArrayDeque;
import java.util.Deque;
public class ValidParentheses {
public boolean isValid(String s) {
if (isEmptyString(s)) {
return true;
}
if (isOddLength(s)) {
return false;
}
int length = s.length();
Deque<Character> stack = new ArrayDeque<>(length);
for (int i = 0; i < length; i++) {
if (isOpenBracket(s.charAt(i))) {
stack.addFirst(s.charAt(i));
} else if (stack.isEmpty()) {
return false;
} else {
boolean isMatchingClosingBrace = isValidClosingBracket(stack, s.charAt(i));
if (!isMatchingClosingBrace) {
return false;
}
}
}
return stack.isEmpty();
}
private boolean isValidClosingBracket(Deque<Character> stack, char c) {
return switch (c) {
case ')' -> (stack.removeFirst() != '(') ? Boolean.FALSE : Boolean.TRUE;
case ']' -> (stack.removeFirst() != '[') ? Boolean.FALSE : Boolean.TRUE;
case '}' -> (stack.removeFirst() != '{') ? Boolean.FALSE : Boolean.TRUE;
default -> throw new IllegalStateException("Unexpected value: " + c);
};
}
private static boolean isOpenBracket(char c) {
return (c == '(' || c == '[' || c == '{');
}
private static boolean isEmptyString(String input) {
return (null == input || input.trim().equals(""));
}
private static boolean isOddLength(String input) {
return input.length() % 2 != 0;
}
}
In case you want to read more about the new switch construct which was introduced in Java 14, I have a post which introduces you to the same.
Conclusion
This problem of parentheses matching must be solved in many computing applications. One such application is in compiler construction, where the compiler needs to determine how the different kinds of parentheses match up with each other in the source code.
The overall code is simple. It was quite important to identify and understand the usage of a stack to solve this problem. Once we realized that the stack is the appropriate data structure, it was important to use the ArrayDeque class to implement the functionality of the stack. Towards the end, we refactored the code which is something you should always strive for. Start refactoring once you have the basic working code. Clean code plays a very vital role in the long run !
In this post we are going to solve the problem of finding the longest common subsequence. Driven by examples, we will begin by thoroughly understanding the problem and then look at an efficient technique to get to the solution. With this foundation, we will start writing the code in Java.
I have written a detailed blog on finding the longest common substring in Java. That post gives you a step by step explanation about why we chose a 2 dimensional array to represent the two strings, the technique applied to arrive at the solution and a complete walkthrough of the code. We will be using a very similar approach to solve the longest common subsequence problem but there are a few important differences between the two problems. Hence, in this post, we will concentrate mainly on the differences but I will also highlight some of the common points with respect to the solution between these two problems.
What is the meaning of longest common subsequence?
We know that a string is composed of characters. In the longest common substring problem, we need to find the common characters between the two strings but the characters have to be contiguous. In longest common subsequence problem, it is a subsequence, it does not have to be contiguous, that is the main difference! Let’s look at some examples.
Difference between longest common subsequence and longest common substring
As shown above, in the first example, when the input strings are “instagram” and “instantgrammar”, the first string, “instagram” occurs as a subsequence in the second string and it is also the longest among others. In the 2nd example, the longest common subsequence between “facebook” and “brook” is book. Finally, in the 3rd example, it is the complete string,tiktok, appearing as the longest common subsequence in ticktock.
Logical approach – Applying dynamic programming
We applied dynamic programming to solve the longest common substring problem. We will be using the same technique for this problem as well. The key to dynamic programming is –
Breaking down the main problem into subproblems.
Solving a subproblem by using the solution from the previous subproblem and then storing the solution to the current subproblem.
If we have two strings and reference the characters at a given index using ‘i’ and ‘j’, we need to find an answer to the question- “What is the longest common subsequence at i , j ? “. In the longest common substring, the answer is- The longest common substring at [ i , j ] is: 1 plus the longest common substring at [ i- 1, j- 1 ] , provided the characters at ‘i’ and ‘j’ are equal. Can we say the same about the longest common subsequence ? Let’s find out.
Finding out the longest common subsequence at a given index
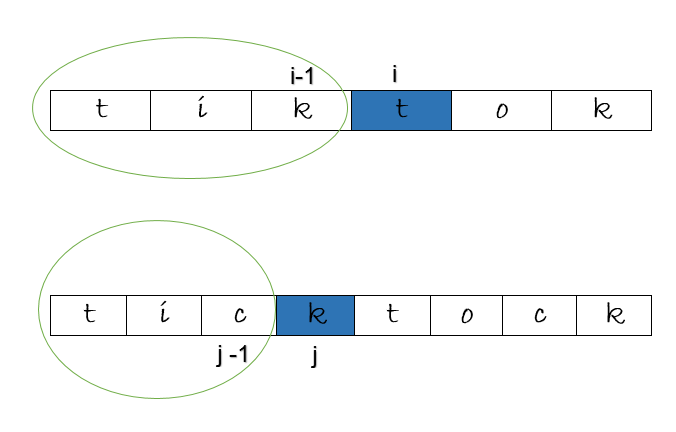
Longest common subsequence at [i ,j] is not equal to [i -1 , j -1] when charAt[ i ] != charAt[ j ]
The characters under consideration at i and j as shown above, are ‘t’ and ‘k’ respectively, they are are unequal. Is the length of the longest common subsequence at [ i , j ] equal to the longest common subsequence at [ i – 1, j – 1 ], the previous subproblem ? If this is true, it would give us 2. But, it is not true ! If you look at the input strings, it is 3, the subsequence, “tik”.
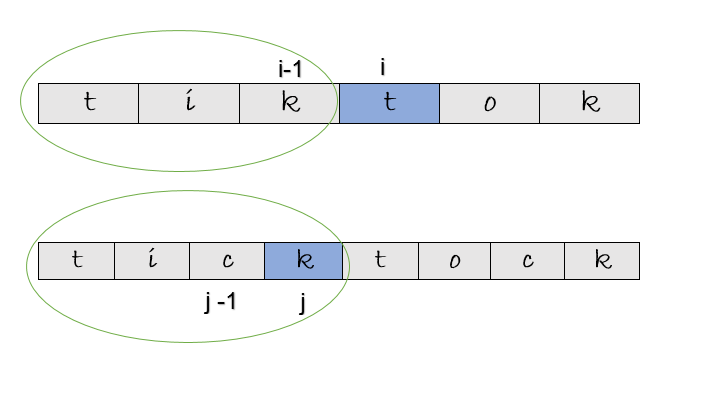
Is the longest common subsequence at [ i , j ] , [ i-1 , j ] ?
Here, we see that the right answer is [ i -1 , j ]. At this point, “tik” is the longest common subsequence having a length of 3. But, is that check sufficient ? Let’s take a look at another example.
Longest common subsequence at [i , j] is not at [ i-1 , j -1] when charAt( i ) != charAt( j )
In this example, the characters at [ i , j ] are ‘a’ and ‘b’ respectively, they are not equal. As you can see, the longest common subsequence is not at [ i -1, j -1 ], this will give us 0. Will [ i -1 , j ] give us the right answer ?
Is the longest common subsequence at [ i- 1 , j ] ?
Well, in this example, it is not [ i -1 , j ] either. This will give us 0 but the right answer is 1, it is the character ‘a’. How do we get it ?
Longest common subsequence is at [i , j – 1 ]
The answer is the longest common subsequence at [ i , j-1 ] as shown above. In one case, when the characters at [i , j] were unequal, the longest common subsequence at [ i , j ] was at [ i -1 , j ] and for another one it was [ i , j – 1 ]. How do we decide which one to take ?
In football, the Golden Shoe award is given to the leading goalscorer in league matches from the top division of every European national league. Similarly, to find the longest common subsequence, we just take the maximum of [ i – 1 , j ] and [ i , j – 1 ]. To conclude, if the characters at [ i , j ] are not equal, the longest common subsequence at [ i , j ] is the maximum of { [ i , j -1 ] , [ i -1 , j] }.
Summary of the logical approach
If the characters at [ i , j ] are equal, the answer is 1 + the value at [ i – 1 , j -1 ]. This is the same as longest common substring.
If the characters at [ i , j ] are unequal, the answer is to take the maximum value from: [ i , j -1 ] and [ i -1 , j ].
Let’s take a took at a snapshot of our two dimensional array if we were to apply these 2 steps.
Partial results for longest common subsequence
The input strings are tiktok and ticktock. We compared each character in a row against a column in the longest common substring, we will follow the same procedure in longest common subsequence. When the first characters, ‘t’ in these strings are compared, they are equal. Hence, the value is one added to diagonal, which gives 1. Similarly, the comparison between ‘i’ in tiktok and “ticktock”, gives us 2 , one added to diagonal value.
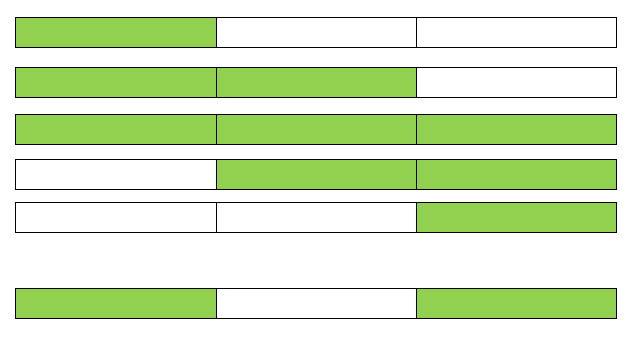
When we compare the character ‘i’ with ‘c’, they are unequal. Here i = 2 and j = 3. So we need to consider : [ i – 1 ] [ j ] = value at [1] [3] = 1 , and [ i ] [ j – 1 ] = value at [2] [2] = 2. The maximum between 1 and 2 is 2. This is indicated with green color above.We apply the same process for the rest of the table. Note that [ i -1] [ j ] indicates the previous row and the same column, and [ i ] [ j -1 ] is same row but previous column.
Result shows complete table with common subsequence with a maximum value of 6
The table above shows you the result at the end of the procedure. As we can see, the length is 6, it is the length of the string, “tiktok”, which is the common subsequence between the two strings.
Breaking down the code
Logic for the comparisons
The code for creating and initializing the 2-d table remains the same as the code for finding the longest common substring. The major change involved is in the step when the characters under comparison are different.
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (x.charAt(i - 1) == y.charAt(j - 1)) {
lcsTable[i][j] = 1 + lcsTable[i - 1][j - 1];
if (maxLength < lcsTable[i][j]) {
maxLength = lcsTable[i][j];
maxRow = i;
maxColumn = j;
}
} else {
lcsTable[i][j] = Math.max(lcsTable[i - 1][j], lcsTable[i][j - 1]);
}
}
}
If the characters at an index [i , j ] are not equal, the code on line 11 takes care of finding the maximum of 2 values. If you need an in depth explanation of of the other lines in the code, please refer to my earlier post on finding the longest common substring. The code above will fill up the table with appropriate values.
Retrieving the longest common subsequence
Now that we have our table ready, it’s time to get the actual common subsequence with the longest length. The maxLength, maxRow and maxColumn values are maintained for the same purpose. The values in maxRow and maxColumn reflect the cell where the maximum length was found.
To get the actual subsequence,we travel backwards with the same logic we travelled forward. If the characters at a particular index [ i , j ] or [row, column] are equal, we take that character and move backwards to the diagonal. If they are unequal, we decide the maximum between [ i – 1 , j ] and [ i , j – 1 ]. If [ i -1 ] [j] is greater, we go to the previous row else to the previous column. This is simply a reduction in index value of either i or j.
Tracing backward to get the actual longest common subsequence
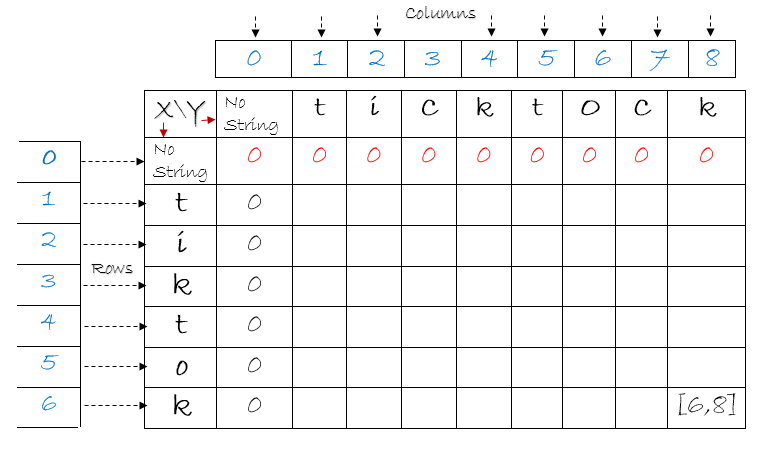
To help you to trace backwards, start at [ 6, 8] which shows a maximum length of 6. Notice the row and column number along with the character. If they are all in same color, it’s a match and we go to the diagonal. Now, we are at cell [ 5, 7 ]. The previous row is [4 , 7] and previous column is [5 , 6 ], see the length shown in circles ( full and dotted). We take the maximum value(full circle) and decrement either the row number or column number by 1.(In his case it is the column number). This is just the exact opposite of how we filled the value at cell, [ 5 , 7 ]. The code for this track back is-
package ds;
public class LongestCommonSubsequence {
private static String findLongestCommonSubsequence(String x, String y) {
int m = x.length();
int n = y.length();
int[][] lcsTable = new int[m + 1][n + 1];
int maxLength = 0;
int maxRow = 0;
int maxColumn = 0;
// init first row with 0
for (int i = 0; i < m; i++) {
lcsTable[i][0] = 0;
}
// init first col with 0
for (int j = 0; j < n; j++) {
lcsTable[0][j] = 0;
}
// starting from 1 as row 0 and col 0 filled with 0. <= since it has go up to
// string length.
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (x.charAt(i - 1) == y.charAt(j - 1)) {
lcsTable[i][j] = 1 + lcsTable[i - 1][j - 1];
if (maxLength < lcsTable[i][j]) {
maxLength = lcsTable[i][j];
maxRow = i;
maxColumn = j;
}
} else {
lcsTable[i][j] = Math.max(lcsTable[i - 1][j], lcsTable[i][j - 1]);
}
}
}
StringBuilder longestSubsequence = new StringBuilder();
//Remember that row 0 and column 0 indicate absence of one of the strings.
while (maxRow >= 1 && maxColumn >= 1) {
if (x.charAt(maxRow - 1) == y.charAt(maxColumn - 1)) {
longestSubsequence.append(x.charAt(maxRow - 1));
maxRow--;
maxColumn--;
} else {
if (lcsTable[maxRow - 1][maxColumn] >= lcsTable[maxRow][maxColumn - 1]) {
maxRow--;
} else {
maxColumn--;
}
}
}
return longestSubsequence.reverse().toString();
}
public static void main(String[] args) {
String a = "tiktok";
String b = "ticktock";
String longestCommonSubsequence = findLongestCommonSubsequence(a, b);
System.out.println("The longest common subsequence is " + longestCommonSubsequence);
}
}
Since we are tracking backwards now, notice that on line 58, we reverse the string.
Conclusion
Using the technique of dynamic programming, we were able to find a solution to this problem. A 2 dimensional array was sufficient to store the length found at every position in the two strings. By addressing a subproblem and storing the results in a table, we were able to determine the result for the next subproblem. The time complexity of finding the length of the longest common subsequence is O(m * n) where ‘m’ and ‘n’ are the lengths of the two strings.
The code for the longest common subsequence and longest common substring have a lot in common but I decided to keep them in separate blogs. I did not want to put everything into one post, I personally think keeping it separate will help you understand both better.Understanding longest common substring first followed by subsequence is a good idea.
In this blog we are going to solve the problem of finding the longest palindromic substring. We will begin our journey by understanding the theory behind it and then, guided by examples, we will a take a detailed look at the approach to the solution.Finally,we will write the code in Java. Every corner condition in the code will be explained with appropriate examples so that you get a complete understanding of the code.
Understanding the meaning of longest palindromic substring
The input that is given to us is a string and we need to find the longest palindromic substring. Let’s break this down a little bit.
A substring is part of a string, a continuous sequence of characters in a string. If the input string is “abracadabra”, every single character is a substring. Strings like “ab”,”br”, “da”,”ra”, “abr”,”dabra” etc are all substrings. What is not a substring is “dbra” since it is not a continuous sequence of characters(‘a’ is missing) in abracadabra.
A palindrome is a word, phrase or a sequence of characters that reads the same backward as forward. Some examples of palindromes are kayak, rotor, or the names Hannah and Ava. You read it in the forward or backward direction and you get the same sequence of characters. Having understood the meaning of a substring and a palindrome, let’s understand the meaning of a palindromic substring.
In abracadabra, the highlighted string, “aca”, is a substring. It is also a palindrome and hence a palindromic substring. Another example is the substring,abba, in the string, dabba. By the way, dabba is an Indian-style tiffin box. Having understood the meaning of palindromic substring,we are left with finding the longest among them. Let’s jump on to an example right away.
Multiple palindromic substrings
As you can see in the above string, 3 palindromes have been highlighted. The first one, shown in red color is “ABA”, it has a length of 3. Then we have the palindromic substring, “ABCDEDCBA”, which is of length 9. Finally, we have the 3rd palindromic substring, “1234567887654321” which has a length of 16, which is the largest palindromic substring. With this understanding, let’s go ahead and analyse the approach to solve this problem.
Logical and technical analysis of the solution
A palindrome reads the same forwards as backwards. Let’s consider the strings rotor, dabba, bob and otto. Other than the fact that they are palindromes, what do you see?
Middle point in any palindrome
A very important observation is the fact that the center of a palindrome is either :
A single character in the middle and the rest of characters are a mirror image on either side of that character.
Two similar characters in the middle and then the rest of the characters are mirror images.
Given a string, we can look at it and then decide if it is case one or case two. But from the perspective of writing code, we will need to handle these 2 cases. I urge you to read and understand these 2 cases again since it is a very important factor to understand the solution from a theoretical and technical point of view.
This can occur anywhere in the string, it could be the first few characters in the string, it could be the last few characters, in the middle or elsewhere.
A quick overview of indexes in a string
The index in a string starts from 0. If the total length of the string is ‘n’, the index ends at n-1. I know you already knew this but a quick refresher always helps.
String index starts from 0 and ends at n-1 for a string of length ‘n’
In every image and example so far, have you observed a dotted box around the center of the palindrome? It’s either a single character or 2 similar characters. I want you to imagine the case with 2 similar characters in the middle as a single one. Just remember this, we will revisit this soon. Now, let’s look at the procedure to get to the solution considering the 2 cases about the center of the character.
Logical steps to get to the answer
We know that around the center of a string, which is a palindrome, the characters on the left and right must be a mirror image. If they are not, it is not a palindrome.
General procedure
We assume that each character in a string is a central point of a potential palindrome. With that as our reference, we compare the character on the left side with the right side. If they are equal, we continue checking by moving further towards the left and right. If they are unequal, we move to next character which will again be considered as a potential central reference.We need to keep on repeating this procedure until we reach the end of the string. At each step, if we find a potential palindrome, we need to maintain the length so that at the end of it , we can find out the one with maximum length. This will be the overall procedure.
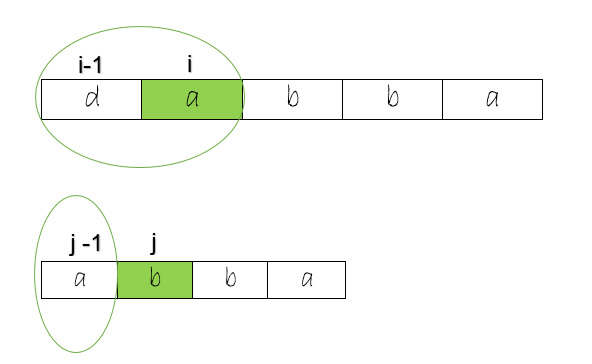
The case of two characters in the middle
Do you remember the 2 scenarios about the character(s) at the center ? The first case has a single character in the middle. The 2nd case has 2 characters in the middle and here, the characters will be next to each other. How do we decide which one to take ?
For every character under consideration, we check for a palindrome considering both cases but take the maximum length of the two. Remember, we can visually see and determine it, but both cases needs to be dealt with in the code. These 2 cases need to be part of the general procedure described earlier.
A visual representation of the procedure
Procedure to find the palindromic substring up to ‘b’
Notice that for each index, we are checking the two cases and then moving to the next character. The execution continues below for i = 2.
Procedure continues with i =2 and centre as ‘bb’
Some of the important things to notice about this procedure are the following:
We iterate through the string only once.
When we move the towards the left and the right after considering a center point, we need to ensure that we don’t move towards the left, beyond the first character and the same holds true for the movement towards the right.
Towards the end of the procedure, we are able to find out the maximum length of a palindromic substring, but we need to also find out what that substring is. In the above case, it is “abba”. To do this, we will need to maintain the starting and ending indices of a substring whose length is maximum at any given point in the procedure.
Technical analysis to arrive at the complete code
We need to fix or assume each character as the center point and start exploring towards the left hand side and right hand side to check if it is a palindrome. I know I am kind of reminding you again, but consider the 2 cases – single character as center and 2 characters at the center. We need to find the maximum among the two.
Iterating ‘n’ times where ‘n’ is the length of the string
Let’s name the method which checks for the matching characters on the left and right as “exploreFromCenter”. This method will keep checking if the characters on the left and right of that middle point are the same and return the length of the palindrome.
for (int i = 0; i < s.length(); i++) {
int lengthSingleCharacter = exploreFromCenter(s, i, i);
int lengthTwoCharacters = exploreFromCenter(s, i, i + 1);
int length = Math.max(lengthSingleCharacter, lengthTwoCharacters);
}
A ‘for’ loop is required to consider each character as the middle point. We call the method, exploreFromCenter, which returns the length of the palindrome. It is called twice for the 2 cases. The first time, it is called with ‘i’ and the second time with ‘i+1’. Note that we are not changing the value of ‘i’ in this step.
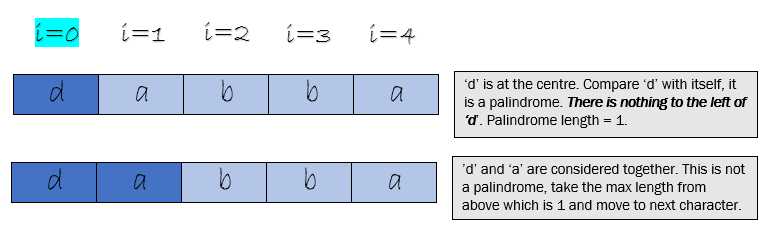
When i = 0 , ‘d ‘ is the center and then ‘da’
Code for exploring around the central character
private static int exploreFromCenter(String s, int left, int right) {
if (s == null || left > right)
return 0;
while (left >= 0 && right < s.length() && s.charAt(left) == s.charAt(right)) {
left--;
right++;
}
return right - left - 1;
}
Other than the input string, the input to this method is the index of the single character or indices of 2 characters, current index and the next one.
Since we are moving towards the left and right by one, we decrement left index by one and increment right index by one. But, we cannot move the left and right index endlessly, can we ? We move only upto the first character, hence the condition left>=0. We can move the right pointer upto the last character and hence the condition, right < s.length(). Note, it is < than and not <= since we want to move upto the last character, strings begin from index 0.
The last line of code, right – left – 1 , which returns the length of palindromic substring needs a bit of explanation. I hope the image below will give you a good idea about the same.
Explanation for the ‘right-left – 1’ in the code on the last line
Code for maintaining the largest length of the palindromic substring
We started writing the code with the ‘for’ loop which handled the 2 cases and found the maximum length among those 2 cases. But this happens for every character in the string. We also need to maintain the maximum length among all the substrings that we have found so far. How can we do that when the method, ‘exploreFromCenter’, returns only the length ?
We need to maintain the start and end index of each palindromic substring we have found so far. This start and end index will point to the first and last character of the palindromic string. Each time we find a bigger palindrome, we update/reset the start and end indices.The final positions of the start and end indices should give us a reference to the actual substring. Let’s expand our initial code further to incorporate this logic-
private static String findLongestPalindromicSubString(String s) {
if (s == null || s.trim().length() == 0) return "";
int start = 0;
int end = 0;
for (int i = 0; i < s.length(); i++) {
int lengthSingleCharacter = exploreFromCenter(s, i, i);
int lengthTwoCharacters = exploreFromCenter(s, i, i + 1);
int length = Math.max(lengthSingleCharacter, lengthTwoCharacters);
if (length > end - start + 1) {
start = i - ((length - 1) / 2); //length -1 for even length strings
end = i + (length / 2);
}
}
return s.substring(start, end + 1);
}
We have initialized the start and end indices to zero on lines 5 and 6. Later, we reset and maintain the indices to the largest palindrome. Remember, once the middle character is fixed, the left and the right index equally move by 1 until matching characters are found. This should give you an insight into lines 16 and 17.
Why does the start index subtract 1 from the length but end index does not ?
Since we have moved equally towards the left and the right and we have a reference to the center, we think that the total length divided by 2 will give us the actual result. But it does not, let’s go ahead and understand the reason behind this.
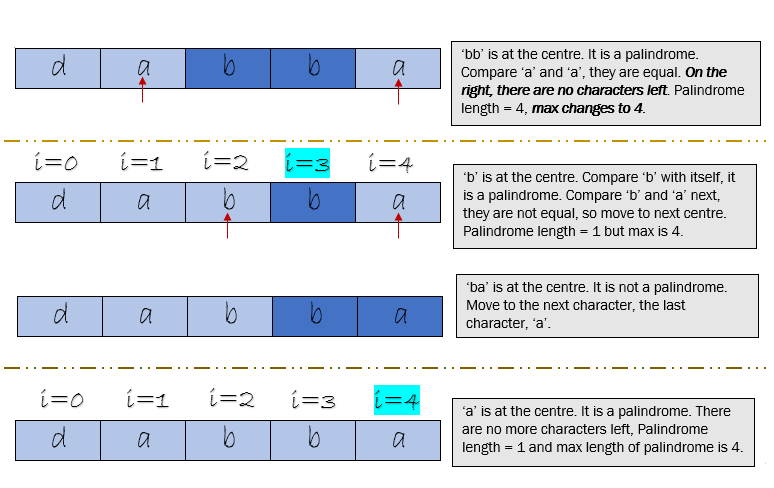
Retrieve rotor with i =2 and length of the palindromic substring as 5
When the input is “rotor” and i = 2, the 1st case where the single character is in the middle returns a palindromic length of 5. We need to find the start and end indices based on this. We do that with the help of the fact that i = 2 and we have moved equally towards the left and right. How do we get to the character ‘r’ on the left side in ‘rotor’ based on i = 2 and length = 5? We need to subtract something from ‘i’ and with the same logic, add something to ‘i ‘ to reach ‘r’ on the right side. Using this logic, if we were to do the following, we think we have the right result.
start = i - (length / 2);
end = i + (length / 2);
This seems to work. Since the length is 5, length /2 gives us 2. The value of i is also 2. So, 2 -(5/ 2) is equal to 0, this is where we want our start index pointer. The end index is calculated as 2 + (5/2) which gives us 4. Note that the length of the palindromic substring is 5 and it has a single character in the middle.
But let’s consider another example now, the one which we have been looking at for a long time now, dabba, which is making me a little hungry now ! But hold on, we are almost there, let’s understand this and then go and get our dabba.
Getting the substring “abba” from the length and current index of middle character.
The value of the start index is calculated as i – (length/2) which gives us 2 – ( 4/2) = 0. This will take the start index to 0. This is an incorrect result. The end index is calculated as i + (length/2), which is 2 + (4/2) = 4, this is where we want our end index to point to. To fix the logic for the start index, we need to subtract one from the length and then divide by 2.
start = i - ((length - 1) / 2);
end = i + (length / 2);
With this fix, start index will be 2-((4-1)/2) = 2 -(3/2) = (2 -1) = 1. This needs to be done for palindromes which are of even length and the fact that there are really two characters virtually considered as one in the middle.This needs to be adjusted in the total length. When i =2, we executed a call to the function,exploreFromCenter, but we sent the value of i and i+1.
The last line which makes a call to the substring function has end +1 as the 2nd parameter. This is done because the function,substring, returns all characters before that index, it does not include the character at the index specified as the second parameter.
Complete code
package ds;
public class LongestPalindromicSubstring {
private static String findLongestPalindromicSubString(String s) {
if (s == null || s.trim().length() == 0) return "";
int start = 0;
int end = 0;
for (int i = 0; i < s.length(); i++) {
int lengthSingleCharacter = exploreFromCenter(s, i, i); // Single character in the middle.
int lengthTwoCharacters = exploreFromCenter(s, i, i + 1); //Two characters in the middle .
int length = Math.max(lengthSingleCharacter, lengthTwoCharacters);
if (length > end - start + 1) {
start = i - ((length - 1) / 2);
end = i + (length / 2);
}
}
return s.substring(start, end + 1);
}
private static int exploreFromCenter(String s, int left, int right) {
if (s == null || left > right)
return 0;
while (left >= 0 && right < s.length() && s.charAt(left) == s.charAt(right)) {
left--;
right++;
}
return right - left - 1;
}
public static void main(String[] args) {
String answer = findLongestPalindromicSubString("HYTBCABADEFGHABCDEDCBAGHTFYW1234567887654321ZWETYGDE");
System.out.println(answer);
}
}
Conclusion
We were able to solve this problem with an overall time complexity of O(n2). We used a single ‘for ‘ loop but for each character we had to compare, move indices around to find the maximum length of the palindromic substring. Overall, the code is not difficult but there are some corner cases, adjustments which we had to handle in the code and these cases can be difficult to understand without going through multiple examples.
I hope you have not only got an answer to the ‘how’ parts of the solution but also the ‘why’ parts of it. Just remember the two cases about the single character or two characters in the middle and you will definitely be able to come up with the code.
Can we improve the time complexity ? Yes, we can ! This can be done using Manacher’s algorithm. But right now, I am definitely going to grab my ‘dabba’ , what about you ?
In this blog we are going to solve the problem of finding the longest common substring between two strings. Guided with examples, we will begin by getting a thorough understanding of the problem and the solution. We will then look at the approach theoretically and finally we will move on to write the code in Java. Like always, I will be explaining each line of the code so that you get a good understanding of not just the ‘how’ sections of the code but also the ‘why’ sections of the code.
What is the longest common substring ?
We are given two strings as input and we need to find the longest common substring between them. What does longest common substring really mean ? Let’s break the problem down, let’s understand the meaning of each word in ‘longest common substring’.
A substring is a part of another string. A common substring is a part of the string that occurs in both the strings. Longest common substring is not just a part of string that occurs in the two strings but also has the biggest length. Let’s look at some examples to understand this better.
Examples of longest common substring
Examples of longest common substring
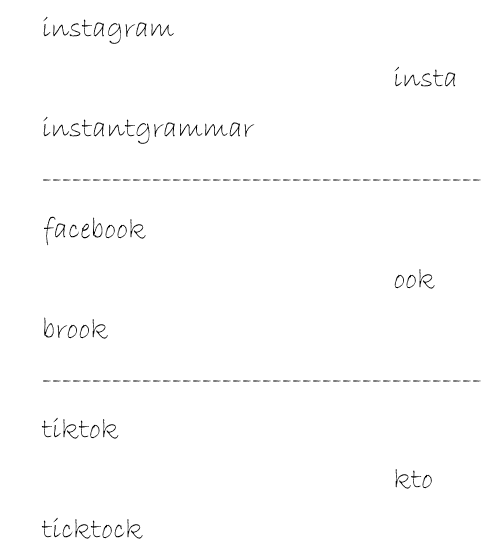
In the first example, the input is “instagram” and “instantgrammar”. There are many common substrings like “i”, “in”, “sta”, “ram”, “gra” and a few more but the longest is “insta” or “gram” which has a length of 4.
The input in the second example is “facebook” and “brook”. It might seem like “book” is present in both strings but note that it does not occur as a continuous string and hence not considered as a valid outcome. The right solution is “ook” .
Finally, when the input is “tiktok” and “ticktock”, there is a “ti” , “to” and “kt” common to them which have a length of two. There are substrings with the single matching characters as well. But the longest common substring is “kto” which occurs right in the middle of the two strings.
Now that we have understood the problem, the solution, and the meaning of the words, longest common substring, let’s go ahead and understand the technique that we will use to solve this problem.
Technique applied to arrive at the solution
Brute force ?
If we are given 2 strings as input, we need to find the longest common substring. When we think of a substring, the immediate solution that comes to mind is comparing the strings. What might seem like a simple approach to arrive at the solution is probably the following-
We start by comparing first character from the first string with every character in the second string.
If they are equal at some point, we will then have to compare the next character from the first string and look at the next character in the 2nd string and check for equality.
At the end of step 1, if we don’t find a matching character in the second string, we will move to the next character in the first string, start comparing it with every character in the second string and repeat the same procedure.
Between all these comparisons, if are able to find a common substring, we will also have to maintain the length of each one. This will enable us to find the length of the longest common substring.
This approach might seem simple but this brute force solution seems to be systematically listing all the possible candidates or combinations for the solution and keeps checking if it satisfies the condition of the solution. Let’s take a look at a better solution.
Using a table or a matrix to store results
What is clear is that we need to compare the characters in each string and find a matching substring that has the biggest length.
At any given point or index in the strings, if the characters are equal, what will be the length of the common substring at that index ? If we were to represent current characters under comparison with indices i and j, and the characters are equal, the length of the longest common substring will be the length calculated upto the index, plus one.
Length of longest common substring at an index
When the characters are equal as shown using red arrow on top half of the image,what is the length of the substring at that point ? It will be the length of the common substring before that, plus one. So for this particular string, it will be one, it is the first common string since we have found nothing common at the previous index.
Similarly, in the bottom half the image, the length of the common string will become one plus the previous value. In this case, it will be 2. So we could generalize this a little bit and say that- At any given index, i , j of two strings, if the two characters at i and j are equal, the length of the common substring will be length at ( i – 1, j – 1 ) + 1 .
What we have done by deducing this is actually solved a subproblem. We are able to find the length at a particular index, which is a part of the main problem. What we are also doing is making use of the results from the previous index which is the previous subproblem. This technique is called dynamic programming.
During every comparison , we need to store the length at the appropriate indices. We have 2 indices, i and j. Let’s try and represent the 2 strings using a 2-dimensional matrix as shown below.
2 dimensional matrix to store the lengths
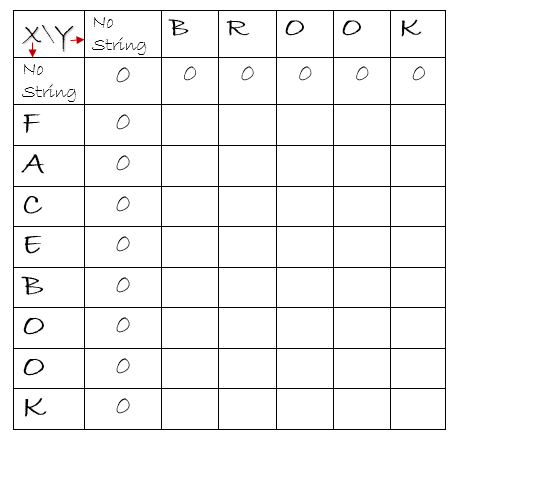
If we are given 2 strings, x and y as “facebook” and “brook”, respectively, we could represent it as shown above. This is a row,column format where a particular [row, column] combination represents a character each from the two inputs strings. The extra row and column represents a case when the input string is empty. The 0 in that row and column will represent that the length of common substring is zero when one of the the strings is empty.
How to make use of this representation?
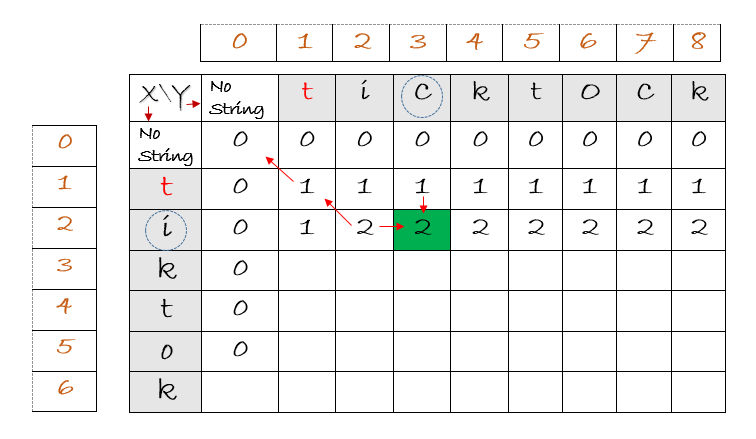
We start comparing the characters in the two strings. If they are not equal,we enter a 0. What if they are equal ? Do you remember the generalized case ? If they are equal, at any index, [ i , j ] , the length will be [i – 1, j – 1] + 1. What is the cell [i -1 , j – 1] ? If ‘i’ represents the row and ‘j’ the column, it means the value at the previous row and previous column, it is the diagonal. Let’s take a look-
Obtaining the value at [i , j] using diagonal element
If we are at i = 2 and j = 1, [2,1] , it represents the 3rd character in first string and 1st character in 2nd string. If they are equal, we need to get the length of [i -1 , j -1 ]. So, reducing the row and column value by 1 in [ 2 , 1 ] gives us [ 1, 0] which is the diagonal element. We add one to the value at diagonal element and store it at that cell. This will indicate that we have found another continuous matching character and the length is 1 more than the length of the previous substring.
With this representation in place, we need to fill this table up with values corresponding to the comparison. The logic during this comparison will be:
If the characters are equal, add 1 to the value at the diagonal and store the value at cell under consideration.
If they are unequal, enter 0 at that cell.
With this 2 step procedure, the strings “facebook” and “brook” can be represented as follows-
We start by comparing the character ‘F’ in “FACEBOOK” with every character in the string “BROOK”. If there is a match, we add one to the value at diagonal and enter this value at corresponding cell. If they are unequal, we simply enter 0 in that cell.
As you can see, we have a few substrings. To track some of them, simply look at the cell with a value greater than or equal to one. Some of the substrings are “B”,”O”. A substring of length 2 indicates the substring “OO” after we match the 2nd ‘O’.
Finally, we can see a substring of length 3. We got this value because of a matching “OO” before the matching “K”. The value at this cell is obtained by adding 1 to the value at diagonal element which has value 2. We have reached the end of the strings.
Tracking the longest common substring
We made use of a two dimensional table and filled each cell with the length at a particular index, [ i , j ], of the 2 strings. When we reached the end, we were able to calculate the length of the longest common substring. That is definitely what we need, but in addition to that, we also need to know what the substring is. Let’s revisit our table with some additional information.
Table shows row and column values for longest common substring
The table above shows row and column values as well. Can we make use of the row and column values to track the string “OOK” ? We have found the maximum length, 3, which is shown at the bottom right corner. What row and column does it belong to ? It belongs to [8 , 5]. Mapping this row number 8 to the 8th character in the string,”FACEBOOK”, which character do you see at that position ? The letter at that position is K. This can be accessed as character number 8 of the string, “FACEBOOK“. We got our first character! What do we do next ?
We travel the diagonal which is reducing the row number by a value of 1, this gives us 7. Let’s access character number 7 in the string “FACEBOOK”. It is the character ‘O’, we append it to the previous letter, ‘K’. This gives us KO.We got our 2nd character. Taking the next diagonal element gives us row number 6. Accessing character number 6 in the string “FACEBOOK” give us ‘O’. So far, we have “KOO”, 3 characters. We should stop now since the maximum length is 3 and we extracted 3 characters from the table and created a substring out of it. We simply reverse the substring, “KOO” to get “OOK”. We have got our desired result !
An important thing to remember is that in order to get the actual substring, we start the journey along the diagonal from the point that we have found the maximum length. This could be at the end of the string,in the middle or at the beginning. So it’s important to keep track of the maximum length. Let’s look at another example to solidify our understanding.
Largest common substring table for strings “tiktok” and “ticktock”
If the 2 strings are “tiktok” and “ticktock”, the largest common substring is “kto” as shown above. We start tracking the string from the maximum length,which is 3. We access the character at that particular index and take the path of the diagonal three times since the maximum length is 3. That gives us the longest common substring. Having understood the theory with these examples, I think it is time to summarize what we have done so far and move on to the code.
Summary of the technique
We used a table, a 2 dimensional table to represent the two strings. Each cell in this table helped us in representing the length of the common substring at a given point. This gave us a nice { row , column } pair.
We compared each character in the first string with all the characters in the 2nd and filled up each cell in the table with appropriate length-
If they were equal, value was calculated as 1 + [value at diagonal]. Cell at diagonal is [ i – 1 , j – 1 ].
If unequal, value was 0.
We kept track of the maximum length as we progressively filled up the table.
Once we reached the end of table or the string, we picked this maximum value and started travelling across the diagonal since that gave us the longest common substring.
I think we have gone through a lot of theory, we need to get technical now, let’s translate this summary into code.
Step by step analysis of the code
We need a table or matrix to represent the length at each point [i , j] of the strings. How do we represent a matrix like this ? We need to also store the length up to a certain index, [ i , j ]. The strings are of fixed length. We can do this with an array, a 2-d array. Let’s call that array, lcsTable. An array has a size.What should be the size of the 2-d array ? One thing to note is that we have 1 additional row and column filled with zeros to indicate the absence of one of the strings. The number of rows can be the size of the first string and number of columns is the size of the 2nd string. Let’s represent the length of the first and second string with ‘m’ and ‘n’ respectively. Now, our 2-d array can be initialized as follows-
private static void lcs(String x, String y) {
int m = x.length();
int n = y.length();
//to compensate for additional row and column with 0
int[][] lcsTable = new int[m + 1][n + 1];
}
The first row and the first column needs to be filled up with zeros. So we require two ‘for’ loops which accesses lcsTable[i][0] and lcsTable[0][j] and assigns them to 0. The first loop keeps column constant and changes row number and 2nd one keeps row constant and changes column number. The code for this will be-
Fill the first column with zeros
// init first column with 0
for (int i = 0; i < m; i++) {
lcsTable[i][0] = 0;
}
Fill first row with zeros
// init first row with 0
for (int j = 0; j < n; j++) {
lcsTable[0][j] = 0;
}
Logic for actual comparisons
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (x.charAt(i - 1) == y.charAt(j - 1)) {
lcsTable[i][j] = 1 + lcsTable[i - 1][j - 1];
if (maxLength < lcsTable[i][j]) {
maxLength = lcsTable[i][j];
maxRow = i;
maxColumn = j;
}
} else {
lcsTable[i][j] = 0;
}
}
}
At lines 1 and 2, we have a nested for loop. The index ‘i’ iterates through the characters in the first string, x, and ‘j’ iterates through string ‘y’. So each character in the string ‘x’ is compared with the characters in string ‘y’. We have started from index 1 since we have row 0 and column 0 to represent a condition where one input string is empty/missing.
Line 3 checks if the characters are equal. An ‘i-1’ and ‘j-1’ is required since first character in a string begins at index 0 but loop starts from index 1. If they are equal , we access the diagonal cell which is [ i-1, j -1] and add 1 to it.
The variable, maxLength, is required as we need to know the maximum length which can be anywhere in the table and not necessarily at the end.
We have also introduced 2 new variables, ‘maxRow’ and ‘maxColumn’. This will point to the actual cell where the maximum length of substring was found. We will then use these variables to access the substring as shown in the previous examples.
Shows intermediate stage, comparisons begin at [1,1]
Code for retrieving the longest common substring
Once the table is filled and we have completed all iterations, the maximum length is in place. We need to find the actual string. We can use the variables, ‘maxRow’ and ‘maxLength’ for this. When our strings were “tiktok” and “ticktock”, we can see that the value of ‘maxRow’ is 5 and ‘maxLength’ is 3.
Mapping the results of lcs using row values, maxRow is 5 and maxLength is 3
As you can see above , value at cell [ 5 , 6 ] is 3. The row value in [ 5 ,6 ] is 5. If you refer to the string, ‘X’ which is “tiktok” and access 5th character, we get ‘o’. You could consider using the variable,’maxColumn’. In that case the string we must use is “ticktock”. We extract the characters three times since the maximum length that has been found is 3. The code for this will be:
StringBuilder longestCommonSubstring = new StringBuilder(maxLength);
while (maxLength > 0) {
longestCommonSubstring.append(x.charAt(maxRow - 1));
maxRow--;
maxLength--;
}
Finally, don’t forget to reverse the string ! Note that we access the character in the input string by reducing 1 from maxRow. Remember that we have 1 additional row and column and strings begin at index 0.
Putting all the snippets of code together
package ds;
public class LongestCommonSubstring {
public static String findLCS(String x, String y) {
int m = x.length();
int n = y.length();
//to compensate for additional row and column with 0
int[][] lcsTable = new int[m + 1][n + 1];
// to find the maximum length
int maxLength = 0;
int maxRow = 0;
int maxColumn = 0;
// init first row with 0
for (int i = 0; i < m; i++) {
lcsTable[i][0] = 0;
}
// init first col with 0
for (int j = 0; j < n; j++) {
lcsTable[0][j] = 0;
}
// starting from 1 as row 0 and col 0 filled with 0. <= since it has go up to string length.
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (x.charAt(i - 1) == y.charAt(j - 1)) {
lcsTable[i][j] = 1 + lcsTable[i - 1][j - 1];
if (maxLength < lcsTable[i][j]) {
maxLength = lcsTable[i][j];
maxRow = i;
maxColumn = j;
}
} else {
lcsTable[i][j] = 0;
}
}
}
return fetchLCS(x, maxLength, maxRow, maxColumn);
}
private static String fetchLCS(String x, int maxLength, int maxRow, int maxColumn) {
System.out.println("The length of longest common substring is: " + maxLength);
System.out.println("Max Row is: " + maxRow);
System.out.println("Max Column is: " + maxColumn);
StringBuilder longestCommonSubstring = new StringBuilder(maxLength);
while (maxLength > 0) {
longestCommonSubstring.append(x.charAt(maxRow - 1));
maxRow--;
maxLength--;
}
return longestCommonSubstring.reverse().toString();
}
public static void main(String[] args) {
String x = "tiktok";
String y = "ticktock";
String longestCommonSubstring = findLCS(x, y);
System.out.println("The longest common substring is " + longestCommonSubstring);
}
}
Conclusion
We solved the problem of finding the longest common substring by solving the subproblem at a given index where we made use of the earlier results stored in a table. This is the essence of dynamic programming and it is a very effective technique to solve these types of problems. This technique is much better and it is a very good solution as compared to the brute force technique which we saw at the beginning. The time complexity using the dynamic technique approach is O(m*n), m and n are the lengths of the 2 strings.
Can we improve this any further ? Yes, we can! Using a suffix tree we can improve this solution even further but I think the solution using suffix trees deserves to be in another blog.
In this blog we are going to discuss the problem of finding the maximum contiguous sum of elements in an array. Now, that was a mouthful ! Don’t worry, we will break this problem up step by step so that you will get a thorough understanding of the problem and the solution. This problem is also referred to as the Maximum subarray problem.
Our first approach to the solution will be the usage of brute force technique and then we will move on to solve the problem using Kadane’s algorithm. As we write the code in Java, we will keep improving the code so that we get a complete understanding of each line of code required to solve this problem.
What is the maximum contiguous sum in a subarray ?
We have an array of integers as input. The array can contain both positive and negative values. Let’s break the 4 important words in ‘Maximum contiguous sum in subarray‘ :
Subarray means part of an array.
Sum is the addition of the elements of an array.
Contiguous means a sequence, no breaks. Hence, contiguous sum means the addition should be between a sequence of values one after the other without a break.
Maximum contiguous sum is finding the maximum value after adding such a sequence of values.
Let’s look at a few examples to understand this better-
Examples of contiguous and non contiguous subarray
Example of contiguous and non-contiguous elements in array
Barring the last one, all the other examples show contiguous elements in an array. It can be only a single element anywhere in the array. It can be 2,3…n elements as long as there is no break in between. Since these are all part of the array, we refer to them as subarray. In the last example, the green blocks form a subarray but they are not contiguous and hence cannot be part of the solution. Having understood the concept of a contiguous subarray, we need to find the maximum sum contiguous subarray.
Examples of maximum sum contiguous subarray
Examples of maximum sum contiguous subarray, answers are on the right
We have understood the concept of a contiguous subarray, now let’s understand the concept of maximum sum in a contiguous subarray. First, take a look at examples 1,2,3 and 4, they are quite straight forward. Starting from the leftmost element, add the elements one by one without breaking the sequence and try to get a maximum value as shown on the right.
Let’s take a look at example number 5. At first glance, it might seem that the answer is 12. But it’s not ! Let’s start from the left, initially, the sum is 0. Adding 10,the first element in the array, gives us 10. Add the 2nd element, -5 to it, gives us 5. Now we add 12 to it, this gives us a total of 17 which is bigger than 12.
Example 6 is also straight forward. Here, it might seem that 10 + 20 = 30 which is bigger than 20, but note that 10 and 20 are not contiguous. Let’s move to the last example, number 7.
Let us approach example number 7 step wise –
We start in a similar way.Initially, the sum is 0, adding 30, the first element in the array to the sum, gives us 30. The maximum value so far is 30.
Add -40 to it and we get -10. We don’t change the maximum value as it is greater than -10.
Add 20 to it, we get a 10 and we again don’t change the maximum value.
If we were to add 40 to it, we get a 50. At this point, we have a new maximum value of 50. But wait a minute…
If you consider only the 2 last elements which form a subarray and add their values, we get 60, which is bigger than 50. So, 60 is the right answer.
Let’s revisit step 2 and 3. The result upto step 2 is -10. Adding the next element, 20, gives us 10. But when we add that current element,20,the outcome of the addition results in lower value than the current element,20. Let’s rephrase it, the current element has higher value as compared to adding it to previous sum. This means, we can reset the continuity or discard the previous sum. Remember this, it is an important condition to solve this problem.
I hope that makes sense. If the current element by itself has a bigger value than adding it to the previous sum, it means we can discard the previous sum since we are on a quest to find contiguous maximum sum. If we did not do this, the previous sums will act as a deterrent to our overall sum. With this, we also restart the continuity from this point onwards.
Using brute force to solve the problem
Let’s consider the following example
30
-40
20
40
Sample input to find maximum contiguous subarray using brute force
We need to find the maximum sum contiguous subarray. A subarray as we know can be just a single element or a sequence of ‘n’ elements. Let’s take a simple approach to solve this problem.
We put a marker at 30, initialize the sum to 0 and –
Add 30 to the sum , resulting in 30.
Add -40 to current sum, resulting in a sum of -10.
Add 20 to current sum, resulting in a sum of 10.
Add 40 to resulting sum, resulting in a sum of 50.
At every step above, compare the sums to maintain a maximum value among them. At the end, what we have done is explored every possible contiguous subarray from the first element, 30 and found maximum value among them.
Add a marker at -40, re-initialize the sum to 0, maintain the current maximum value from step 1 and –
Add -40 to the current sum, resulting in -40.
Add 20 to the current sum, resulting in -20.
Add 40 to the current sum, resulting in 20.
At each step, compare the sum with the current maximum value to find maximum among them. All possible contiguous subarrays starting from the second element, 40 have been explored.
Add a marker at 20, initialize the sum to 0 and –
Add 20 to current sum, resulting in 20.
Add 40 to current sum, resulting in 60.
At each step, compare each sum with maximum and find maximum among them. All the contiguous subarrays starting from 20 have been explored.
Add a marker at 40, initialize the sum to 0 and:
Add 40 to current sum, resulting in 40,
In this step, compare the sum,40, with maximum obtained in steps above and set appropriate value.
This is the end of the array,we should have found maximum value by now.
Why are we putting markers ? We are putting these markers to have a kind of starting point for the subarray. A subarray can start at every element in the array. For an array of size 4, we put 4 markers. So, I hope you can imagine a ‘for’ loop from 0 – n representing each marker.
What do we do for each marker ? From the element being pinned (Sorry, too much usage of Zoom) as a marker, we first initialize sum to 0. Then we start adding the numbers after that pinned element upto the last element. So, another for loop inside the already existing loop, we get a nested for loop. Inside the nested for loop, we find the sum. So, sum = sum + element. Remember, we need to find the maximum at each step now. This can be done using another variable which will be compared against sum.
Brute force approach
As you can see above, the marker starts at the leftmost element and keeps moving ahead one by one. For each position of the marker, we iterate from the marker upto the end of the array and keep finding the sum. At every iteration ,we evaluate if we have found a new maximum value.
Code using brute force approach
public class MaxSumSubArray {
public static void main(String[] args) {
int[] arr = {30, -40, 20, 40};
int sum = findMaxSum(arr);
System.out.println("The maximum contiguous sum in the sub array is : " + sum);
}
private static int findMaxSum(int[] arr) {
int currentSum;
int maxSum = 0;
for (int marker = 0; marker < arr.length; marker++) {
//reinitialize sum when marker moves ahead.
currentSum = 0;
for (int j = marker; j < arr.length; j++) {
currentSum = currentSum + arr[j];
if (currentSum > maxSum) {
maxSum = currentSum;
}
}
}
return maxSum;
}
}
Notice that on line 20, j is initialized to marker which moves ahead by one each time. We don’t want to find subarrays every time from the first element.
Does the code work for all inputs ?
The input that we passed has a mix of positive and negative numbers. What if we pass the input as a set of all negative numbers ? If we were to pass the input as {-30, -40 , -20 , -40} , we get the output as 0. We need to fix our code to handle this scenario. Take a look at the following code snippet –
As you can see, the maximum sum is initialized to 0. Since all the values in the array are negative values, the current sum is always a negative value, it is never greater than the maximum sum, which is 0. Hence the ‘if’ condition is never satisfied and the maximum sum is returned as 0.
The fix for this is changing a single line of code –
int maxSum = Integer.MIN_VALUE;
With this change, an input consisting of only negative values should work as expected.
Time complexity of the brute force approach
In the code above, there are 2 nested ‘for’ loops. For every position of the marker, we are iterating through the rest of the array. The time complexity of this code is hence O(N2). If you are completely new to the Big O notation, I would recommend this excellent article by Rob Bell.
The solution works and it is a decent way to get started. Once we have a working solution, we should start thinking along the lines of improving the code and the performance of the code. But remember, don’t get obsessed about improving the performance of every piece of code you write !
We can definitely do better in solving this problem by improving the time complexity to O(n). Let’s explore Kadane’s algorithm.
How to pronounce Kadane ?
Before we get started, I would like to sidestep a little bit with respect to the pronunciation of Kadane. We have a cricketer who goes by the name Ajinkya Rahane. His surname, Rahane , is pronounced as Ra-ha-‘nee’ with an emphasis on the ‘ne’. Kadane is not pronounced like that. It’s more like pronouncing the ‘cane’ in sugarcane or the way you pronounce ‘Dane’ when you refer to someone from Denmark. Peter Schmeichel is the most capped Danish footballer of all time, and the first Dane to reach 125 caps. There is no drag on the ‘ne’ in Dane. Similarly, don’t drag on the ‘ne’ in Kadane. By the way, his full name is Joseph Born Kadane, you can read more about him here. Hey Arsenal fans, speaking of Danes, you can’t forget the great Nicklas Bendtner, can you ? Let’s get back to Kadane’s algorithm now.
Kadane’s algorithm
You can get a good overview of the algorithm here. What is important to note is that, at any given index, the algorithm computes the subarray with the largest sum upto that index. Let’s get into an example.
30
-40
20
40
Example for Kadane’s algorithm
This is the same example which we considered when we used the brute force approach. When we went through the process step by step using brute force, do you remember a condition which was going to play a crucial role in solving this problem ?
If the current element by itself has a bigger value than adding it to the previous sum, it means we can discard the previous sum since we are in a quest to find maximum contiguous sum. If we did not do this, the previous sums will act as a deterrent to our overall sum.
Reset the sum since we found a better point for finding max sum continuity
The sum obtained up to the 2nd element is -10. Now, the next element is 20. If we add the previous sum of – 10 to 20, we get 10. However the current element, 20, is bigger than the sum. Why should we carry a baggage of lesser value as compared to the current element which is much bigger ? So, we reset the continuity and now the sum and the maximum value should be 20 from where we move on to the next element.
So in short, we need to take the maximum between the current element and the sum obtained by adding the previous sum to current element. If the current element is bigger, we reset the sum and the subarray. What if it is not ? What if the sum is bigger ? To get our answer , let’s consider the element 40, which is the next element in the array.
What does it mean if the current element is smaller than the sum obtained by adding current element to previous sum ? It means, the sum, the bigger value, can help us further as it has enhanced our overall value as compared to current element. It also means that the previous sum does not act as a deterrent and we continue with our sequence of elements.
Continue with the sum and the sequence since addition is an enabler and not a deterrent
So, in short, for every element in the array, we need to –
Find the maximum value between the current element and the addition of the current element to the previous sum.
If the current value is bigger, we need to reset. It will also give us a new value to the sum so that we can to continue our exploration further in the array.
If the maximum between the two is the value of the addition of the current element and the previous sum, this value becomes the new sum.
Once steps 1, 2 and 3 are done, remember, we need to maintain the max value like we did in the brute force approach.
Code for Kadane’s algorithm
public class MaxSumSubArray {
public static void main(String[] args) {
int[] arr = {30, -40, 20, 40};
int sum = findMaxSum(arr);
System.out.println("The maximum sum in the sub array is : " + sum);
}
private static int findMaxSum(int[] arr) {
int sum = 0;
int max = 0;
for (int i = 0; i < arr.length; i++) {
sum = Math.max(sum + arr[i], arr[i]);
max = Math.max(sum, max);
}
return max;
}
}
In the ‘for’ loop, we have simply translated the theory that we just understood into code. We find the maximum between the current element ( arr[i] ) at hand and the addition of the previous sum and the current element (sum + arr[i]). The one that has maximum value becomes the new sum.
sum = Math.max(sum + arr[i], arr[i]);
Once we have the new sum, we check if it is the new maximum and if it is, we assign it to the variable, max.
max = Math.max(sum, max);
Did you notice that there is a single ‘for’ loop ? There are no nested loops ! The time complexity of this code using Kadane’s algorithm is O(n) which is better than the brute force approach. We only iterate through the elements of the array once. Does the code work for all inputs ? What if we supplied an array of all negative values ? Unfortunately, it does not.
Like the brute force approach, we have initialized the variable, max, to 0. One option is to assign it to Integer.MIN_VALUE, like we did in the brute force approach. There is another way to do it as well, the first element of the array can be assigned to the variables sum and max. We can then start our iteration from the 2nd element onwards.
private static int findMaxSum(int[] arr) {
int sum = arr[0];
int max = arr[0];
for (int i = 1; i < arr.length; i++) {
...
}
return max;
}
Conclusion
We have seen 2 approaches to solve the problem of finding the maximum contiguous subarray. The first approach was simple but it had a time complexity of O(N2). On the other hand, Kadane’s algorithm has a time complexity of O(n), linear time, which is better than brute force. But, unless you know the algorithm before hand, it is difficult to come up with this solution at runtime, like, in an interview. But now I hope that after reading this blog, you will remember Kadane’s algorithm which is quite an effective technique to solve this problem.
If you still can’t remember the algorithm, it’s alright! I am sure that you will at least remember that the pronunciation is not ‘Kadanee..’ !
In this blog, we are going to solve the ‘N’ queens puzzle in Java. We will begin with an overview of the problem, move on to understand the challenges involved in the solution and finally write the code in Java using recursion. As always, I will be explaining the code in detail with proper reasoning. I have also included images where necessary which will help you to visualize the theory and the solution.
In my previous blog, we had a look at the 4 queens puzzle in detail. Using a lot of pictorial representations, we understood the problem and the solution, chose a single dimension array instead of a 2 dimensional array and finally, we went through each line of code in Java. If you are completely new to the 4/8/’N’ queen puzzle, I would recommend that you read that blog first.
What is the ‘N’ queens problem ?
In the 4 queens puzzle, we were faced with the problem of placing 4 queens on a 4 *4 chess board such that no two queens attack each other. In the ‘N’ queens problem, we will have a N * N chess board and try and place ‘N’ queens such that no 2 queens attack each other. Let’s consider N = 8 to begin with. If 2 queens should not attack each other, it means no two queens share:
Same row
Same column
Diagonal
The constraints for the ‘N’ queens problem remains the same as the 4 queens problem. From a code perspective, we will actually reuse the same function, noKill, to check for conflicts. The 4 queens problem had 2 solutions satisfying these constraints. The 8 queens problem has 92 solutions – we can place 8 queens on the 8 * 8 board in 92 different ways which satisfy the constraints mentioned above.
One of the 92 solutions in the 8 queens problem
Logical solution to the puzzle
The steps required to place the 8 queens on the board is similar to the 4 queens puzzle. We take the same approach of placing the queens in a column by column manner. The image above shows how the queens,Q1 to Q8, have been placed in the columns starting from left to right.
As a quick refresher, in order to place the 8 queens without any conflict, we start at the top left corner.The first queen is placed in that square. We move to the 2nd column and find a suitable position in that column which has no conflict with the first queen. Then we move on to the 3rd queen where we will check for conflicts with the previous two queens. This procedure repeats until we are able to place all 8 queens on the board. If we find a conflict at some point, we backtrack to the previous column and move the queen to the next position/row in that column.
Technical parts common to the the 4 queens problem
Handling the results
In the 4 * 4 queens scenario, we initialized a single dimension array of size 4 to hold the results. We will use the same 1 dimensional array but since we have 8 queens to deal with or in fact let’s go ahead and generalize it to ‘N’ queens, we will dynamically initialize a board of size ‘N’.
int [] board = new int[noOfQueens];
The size of the array will be the number of queens we want to place on the board, let’s take that as an input and assign it to the parameter shown above.
The ‘noKill’ function to check conflicts
We wrote the code for this function in the 4 queens problem and this piece of code remains the same for the ‘N’ queens problem as well. We check for same row and diagonal conflicts in the function. Since we place one queen per column, there is no need to do a conflict check for column.
As a quick refresher, the values in the board array will represent the row number of every queen in a particular column, the column serves as an index into the array.
Single dimension array holding one of the solutions to the 8 queen problem
As shown above, the board array will contain [ 0, 4 , 7 , 5 , 2, 6 , 1 , 3 ]. They represent the row number at which a queen is placed. The column number will be the index into the array. So queen number 1 is at { row 0, column 0 } , queen number 8 is at { row 3, column 7 } and so on.
private static boolean noKill(int[] board, int currentColumnOfQueen) {
for (int i = 0; i < currentColumnOfQueen; i++) {
// same row
if (board[i] == board[currentColumnOfQueen])
return false;
// Diagonal
if ((currentColumnOfQueen - i) == Math.abs(board[currentColumnOfQueen] - board[i])) {
return false;
}
}
return true;
}
The code in this function has been explained in detail in my previous blog. Let’s summarize the code in this function-
The ‘for’ loop checks if the current queen to be placed has any conflicts with all previously placed queens. Hence the loop starts from 0 and moves up to one previous column than the current column under consideration.
Row conflicts can be checked by comparing the value in the board array at all previous indices (position of previous queens already placed) with the value at current position under contention. If they are the same, it means we have a row conflict.
A chess board being composed of squares, any diagonal conflict can be detected by the difference in row and column values of 2 squares. If the difference yields the same value, we have a diagonal conflict. As shown below, when we want to place queen 5 , at column number 4, row number 1 , { 1, 4 } , the for loop will check for all diagonal conflicts with existing queens. When that loop runs and i = 1 , Q2 is at { 4 , 1 }. Absolute values of the difference in row and column values yields 3 and hence a diagonal is detected.
Diagonal conflict between Q5 and Q2
Those were the common parts between the 4 queens and ‘N’queens problem. Now, let’s take a look at how to improve the code for 4 queens puzzle and make it cleaner and generic enough to handle ‘N’ queens.
Using recursion to solve ‘N’ queens
We used nested ‘for’ loops while solving the 4 queens problems. In fact we used 4 ‘for’ loops for 4 queens. Since we want to solve 8 queens or in fact ‘N’ queens, the multiple ‘for’ loops is not a viable solution. We need to come up with another solution, recursion will help us here.
When you think of recursion, think of breaking down a big problem into subproblems. You could sometimes apply this philosophy in life too ! We need to place 8 queens, let’s break it down, let’s try and place 1 queen. If we have a function which solves the problem of placing 1 queen with all constraints, we move to the next queen and then we land up doing the same steps again. We can think of placing 1 queen as our subproblem and we have 8 or ‘N’ such subproblems. When we use recursion, the function keeps calling itself.
Well, one cannot keep calling the function recursively, endlessly ! I mean, imagine solving your problems in life endlessly, I mean, we kind of do that but we would definitely like to break that loop, right ?
If you think about the procedure of placing ‘N’ queens, we start from column number 0 at the top left corner, and find positions across the board in each column such that there are no conflicts. When do we stop ? We stop when we place all ‘N’ queens on the board. From a code perspective, we can start from 0 and then as each queen is placed, we can increment that counter. When this counter equals ‘N’, we stop.
When there is a conflict in a particular square, we backtrack to the previous column and move to the next row/position in that column since the current one yielded a conflict. Then the same procedure continues.
Let’s put all of this theory in a function and understand the code-
private static void placeQueen(int[] board, int current, int noOfQueens) {
if (current == noOfQueens) {
displayQueens(board);
return;
}
for (int i = 0; i < noOfQueens; i++) {
board[current] = i;
if (noKill(board, current)) {
placeQueen(board, current + 1, noOfQueens);
}
}
}
The function, placeQueen, takes 3 parameters –
The board array which will maintain the position of the queens placed on the board.
A counter , current, which will initially be 0. This will track the number of queens already placed on the board. Everytime one queen is placed without a conflict, the value will be incremented.
The final parameter is the number of queens that we want to place.
The part of the code which contains the ‘if’ condition simply checks if we have placed all our queens. If we have placed all queens, we return from the function. That is exactly the exit condition for our recursive procedure. I wish it was easy to find an exit condition for all our problems in life !
if (current == noOfQueens) {
displayQueens(board);
return;
}
The ‘for’ loop is a little bit more involved. Let’s take a look at that snippet of code.
private static placeQueen(int[] board, int current, int noOfQueens) {
....
for (int i = 0; i < noOfQueens; i++) {
board[current] = i;
if (noKill(board, current)) {
placeQueen(board, current + 1, noOfQueens);
}
}
}
Let’s understand this code in detail-
The ‘for’ loop iterates ‘N’ times, the number of queens supplied as input.The first step to solve this puzzle is to place the first queen at the top left corner and then place other queens in other columns. But what is important to remember is that the first queen itself will take 8 different positions.
Q1 will iterate 8 times, the solution can have Q1 at any of the positions from 0 -7 in first column
The next line in the code, board[current] = i, fixes the position of the queen in left top corner to begin with. Remember when we call this function the first time, current is equal to 0. Then the call to the ‘noKill’ function will return true since it is the first queen and obviously can’t have conflicts. This means the first queen has been successfully placed. With the 1st queen placed successfully, what’s next ? We move to 2nd column and try to fix the second queen’s position. We discussed that we find and fix each queen’s position using recursion. Let’s make a recursive call.
The recursive call is made by incrementing the counter, current, by 1. We again enter the ‘for’ loop. How many times should this be executed ? What does this do ? It checks if the position of the 2nd queen at {0 , 1 } can be fixed, hence the call to the ‘noKill’ function. In this case, the ‘noKill’ function will return false since there is a row conflict with the first queen. The code comes out of the ‘if’ loop and executes the next iteration in the ‘for’ loop. Now this loop will take care of fixing the position of the 2nd queen again but this time it will try in the 2nd row. How many possible positions are there in this column ? Well, 8 rows, so 8 times. Hence, to answer the previous questions, it could be executed 8 times and what it is doing is, fixing the position of the 2nd queen.
This goes on until we are able to fix the positions of all 8 queens for just the first position of the first queen. At that point, for queen number 8, if the ‘noKill’ function returns true, we would have placed all 8 queens. The ‘current’ value will be 8 , the ‘if’ condition will return, the function returns.
Remember, for the first position in top left corner, the second queen can potentially take 8 different positions in the second column and for each position of the second queen, the third can take 8 different positions and so on for all of them.That is why the recursive procedure is an effective way to solve this problem whether there are 4, 8 , or ‘N’ queens. So in effect, there is a complete branch, both depth wise and breadth wise that is being formed.
A very important part of this recursive procedure is that a recursive call is given ONLY when the conflicts are not there, so there is pruning and branches are formed only when there are no conflicts. If the ‘noKill’ function returns false, we don’t give a recursive call again which in turn avoids the creation of another branch in our recursive tree.
Complete Code
public class NQueens {
public static void main(String[] args) {
int n = 8;
nQueens(n);
}
private static void nQueens(int noOfQueens) {
int [] board = new int[noOfQueens];
placeQueen(board, 0, noOfQueens);
}
private static void placeQueen(int[] board, int current, int noOfQueens) {
if (current == noOfQueens) {
displayQueens(board);
return;
}
for (int i = 0; i < noOfQueens; i++) {
board[current] = i;
if (noKill(board, current)) {
placeQueen(board, current + 1, noOfQueens);
}
}
}
private static boolean noKill(int[] board, int currentColumnOfQueen) {
for (int i = 0; i < currentColumnOfQueen; i++) {
// same row
if (board[i] == board[currentColumnOfQueen])
return false;
// Diagonal
if ((currentColumnOfQueen - i) == Math.abs(board[currentColumnOfQueen] - board[i])) {
return false;
}
}
return true;
}
private static void displayQueens(int[] board) {
System.out.print("\n");
for (int value : board)
System.out.printf(value + "%3s" ," ");
System.out.print("\n\n");
int n = board.length;
for (int i = 0; i < n; i++) {
for (int value : board) {
if (value == i)
System.out.print("Q\t");
else
System.out.print("*\t");
}
System.out.print("\n");
}
}
}
The only additional code above is the display function. It is called each time when all 8 queens have been placed successfully. The function has the board array which has the positions of the queens. A sample of the output can be seen below, here, the number of queens was passed as 8. The first line shows the position( row number) of the queen in each column.
Snapshot of the output from running the code with ‘N = 8’
Conclusion
Using recursion, the code for the ‘N’ queens problem looks quite clean. Recursion is definitely an important and effective technique to solve certain types of problems. However, recursion must be used with caution, if the technique is not used correctly, one could have performance issues.
The code above is definitely more clean and concise but also more involved. I urge you to trace the code with a smaller value of ‘N’ to get a even better understanding of the code and the recursion involved in solving the problem.
I end this blog by leaving you with a snapshot of the trace when N = 4. Some salient points which will make it easier for you to follow the trace-
Follow the numbers on the arrows starting from 1 on the left side, they indicate the step numbers.
The trace starts with the 3 inputs as – the board array initialized to -1, the pointer, current, and finally the total number of queens to be placed on the board.
Some backtracking can be seen by the arrows represented in red colour.The dotted arrows in blue indicate the pruning.
In each box, if the board array values are shown in red color, it indicates either a row or diagonal conflict.
Circle in green signifies that a position for a queen has been found and after that, the value of the counter, current(2nd parameter) is incremented by 1.
Snapshot of tracing when N = 4
References
Excellent lecture on the MIT OpenCourseWare channel
In this blog we are going to take a look at the 4 queens puzzle and –
Pictorially understand the problem and the solution in detail.
Do a step by step analysis of the data structure required to arrive at the solution.
Write the code in Java. I will be explaining each line of code so that you get an understanding of not just the ‘how’ but also the ‘why’ behind a particular line of code.
Why 4 queens and not 8 queens ?
In another blog, we will be solving not just the 8 queens problem but we will be taking a look at the solution to the ‘N’ queens problem. I think it is important to get a good understanding of the smaller and common bits by first considering the 4 queens problem since it is a subset of the 8 queens or ‘N’ queens problem.
We will be choosing an optimized data structure and also handling the different scenarios in the code for the 4 queens problem which will give you a strong foundation. With this strong foundation, you will find it much easier to solve the 8 or ‘N’ queens problem. Let’s go ahead and get a good understanding of the problem.
What is the 4 queens problem ?
It is the problem of placing 4 queens on a 4 * 4 chessboard so that no two queens threaten each other. This really means that no two queens share the same row, same column or same diagonal. Remember these constraints as it is the most important part of the solution and the code.
4 * 4 chess board – 4 rows and 4 columns
Solution to the 4 queens problem
Only 2 solutions to the 4 queens problem
With the constraints mentioned above, there are only 2 solutions to the 4 queens problem. As you can see from the 2 solutions, no two queens share the same row, same column or diagonal. I wanted you to visualise the solution to the puzzle first so that you get a better idea about the approach that we are going to take.
How to get to the solution?
The way to arrive at these solutions is to start at the top left corner of the board and start placing the queens one by one on the board. If we come to a point where we realize that there is a conflict between the queen just placed on the board and one of the existing queens, we simply rule out that step to get to the solution and try placing that queen on another position – this also means we are going back a step. This is also called as backtracking.
When you are in the process of finding a job, ideally, one would: Prepare -> Apply -> Interview. If you fail the interview and find yourself royally underprepared, you would go back and read the things you missed out on before you start applying again- backtracking, something that you don’t always like to do but need to do in order to progress further.
We start placing the queens one by one on the board, the starting position can be column 1 as shown below. Every column will have only 1 queen.The approach we will be taking is placing a queen on each column one by one. One can approach it row by row as well. Once a queen has been placed on a particular position in a column, with all conditions satisfied, we move to the next column.
Trying different positions for the 2nd queen in the 2nd column
As shown above, when we start exploring for a position on the 2nd column, we cannot place the queen on the first 2 positions(shown with an ‘X’) . This is because of a row and diagonal conflict with the first queen. However, the 3rd position seems correct. Let’s move on to the 3rd column now.
Shows need for backtracking as we landed with incorrect result on column 3
So far we have placed 2 queens. As shown above, on the left hand side, when we try to place the 3rd queen in column 3, we are not able to find a suitable position for it because of the position of previous queens. There is a conflict with the first queen because of sharing the same row and a conflict with the 2nd queen because of diagonal and row conflicts. This means we need to go back, backtrack, to the 2nd column and place the queen on next position in the 2nd column – shown on right side in the image above. We continue in this way until we are able to place all the 4 queens without conflicts.
We started by placing the first queen at top left corner. Then we performed the steps mentioned above to place the other queens. This first position of the first queen might give us a solution. We then move on to explore other solutions by placing the first queen again at different positions on the first column. The rest of the grid has been shown in dotted lines to indicate that in each step below, positions of the other 3 queens are yet to be determined. Remember that one column can have only 1 queen.
Different positions of the first queen
Technical deductions
With this understanding, we need to:
Handle a 4 * 4 chess board along with 4 queens.
Choose an appropriate data structure to track the solution/position of the queens.
Handle conflicts when placing the queens on the board.
Let’s take a look at each one of these steps in detail.
Representing a 4 *4 chess board
Row and column layout for a 4 *4 board
A chess board can be represented using a row and column layout as shown above. We have 4 rows and 4 columns starting from row 0, column 0 in the left topmost corner and {3 , 3} at the bottom right representing row and column number 3. Any cell can be represented as { row , column } combination. One approach could be to use a 2 dimensional array to represent the board and the positions occupied by the queen but we are actually not going to use it. We are going to have much more optimized solution in terms of space.
Let’s take a look at the solutions again, mapping them with row and column numbers:
Mapping 2 solutions to row and column numbers on the chess board
2 terms that have occurred repeatedly in the logical approach are the words ‘column’ and suitable ‘position in a column’. We need a data structure to represent this.
Let’s look at solution number 1 – [ {1,0} , {3,1} , {0,2} , {2,3} ] . We know that each column can have only 1 queen, take a look at the column numbers in each of the {row , column} pairs in solution number 1 – { 0, 1 , 2, 3 } . Now let’s single out the row numbers – { 1, 3, 0, 2 }.
Single dimension array to store the position of the queen
As shown above, we place 1 queen in 1 column. The position { 1, 0 } tells us that the first queen is placed at row 1 and column 0. In the 1st column, the queen is on 3rd row and so on for other 2 columns. If we were to separate out the column number as an index to a single dimension array, the value at each index/column will be the row number as shown on the right side of the above figure. From this array, we can actually determine the position of the 4 queens. Index 0 tells us the position of first queen, Index 1 the second queen and so on. Hence a single dimension array is sufficient to represent the position of the queens as compared to a 2-d array.
int [] board = { -1, -1, -1, -1 };
We declare a single dimension array called board and initialize all the values to -1 before we start placing the queens one by one. The size is 4 since we need to place 4 queens.
How to check for conflicts when placing queens ?
Well, no two queens can be placed on –
Same row
Same column
Along the diagonal
The same column will not hold true in our case since we are taking a column placement approach and we have only 1 queen placed on 1 column.
When we attempt to place a queen at a particular position or row in a given column, we need to check that the current queen being placed does not share the same row with an existing queen. How do we check that using the single dimension array ?
2 queens sharing same row . Right side shows 2 scenarios of conflict with Q1 and Q2 on columns 1 and 2
As you can see, using the board array, we can easily determine if 2 queens share the same row. An important point to remember is that when we try to place a queen at a particular position in the current column, we need to check for row conflict with all previously placed queens. Due to this, we need a pointer to current column and a ‘for’ loop which runs from 0 to current column. In this loop we will check if the row values are the same since 2 queens which share the same row will land up having the same value in the board array.
Let’s define a function, noKill, which takes 2 parameters – one is the board array and the 2nd parameter is the current column of the queen being placed.
private static boolean noKill(int[] board, int currentColumnOfQueen) {
for (int i = 0; i < currentColumnOfQueen; i++) {
// same row
if (board[i] == board[currentColumnOfQueen])
return false;
}
return true;
}
When we call this function, we will pass –
The value of the current column under consideration reflected by the 2nd parameter.
The board array – Will have values of the row numbers for each column of previously placed queens. Along with this, we will assign the current position of the queen under consideration in the board array which will be accessed using the 2nd parameter.
Row conflict as Queen 1 and Queen 3 share same row.
Checking for diagonal conflicts is a little bit more involved. We can take advantage of the fact that a chess board is made of squares.
Row/Column difference between diagonal elements
Let’s consider 2 scenarios to understand the diagonal condition better.
The first queen is at { 0 , 0 } and we want to place a queen in column 1 which is where the current column is pointing at. Let’s consider { 1 , 1} which is the diagonal element for queen at { 0 , 0} . Let’s take the difference between the row number and column number starting with the {row,column} of current column under consideration and a queen already placed. This will result in [ {1-0},{1-0} ]. The value of the difference is the same, 1 and 1.
Assuming the first queen is at { 3 , 0 } and we are at column 3 wanting to place the queen at {0 , 3} where current column is pointing. So difference in row number is {0 – 3} and difference in column number is { 3 – 0} . The absolute difference is the same, 3 and 3.
Difference in row and column numbers of diagonal squares
I have shown you just 2 examples but you can consider any of the diagonals on the board and notice that the difference in row and column values land up being the same.
Accessing the column number of the current queen under consideration is simple since we have the a pointer to the current column. Our ‘for’ loop will run from 0 – current column since we need to check the presence of a diagonal with all previously placed queens. We already have a ‘for’ loop for the row check and hence we can utilize that same loop. To get the row value, we access the board array since the board array contains the position of the row at a given column.
The left hand side gives us the difference in column values. The right hand side gives us the difference in row value. The Math.abs function call is required as shown in the previous example where one diagonal can give us a negative value. Add this to the existing code of the noKill function gives us the following-
private static boolean noKill(int[] board, int currentColumnOfQueen) {
for (int i = 0; i < currentColumnOfQueen; i++) {
// same row
if (board[i] == board[currentColumnOfQueen])
return false;
//Diagonal
if ((currentColumnOfQueen - i) == Math.abs(board[currentColumnOfQueen] - board[i])) {
return false;
}
}
return true;
}
That’s the final code for checking conflicts. Using a ‘for’ loop which iterates from 0 to current column, we check if the current queen, which we want to place, has a row or diagonal conflict with any of the earlier positioned queens. If we find a conflict for any queen, the function returns false. If there are no conflicts, the function returns true on the last line.
Calling the noKill function
Dealing with the first Queen
We start with the first queen placed at 0,0 and for this one position, we find appropriate positions for the other queens across the board in columns 1, 2 and 3. There are 3 more positions for which we repeat this same procedure, { 1 , 0 } , { 2 ,0 } and { 3 , 0 }. This is a total of 4 positions, so we need to count 4 times for 4 queens. We need a ‘for’ loop starting from 0, less than n. In each row position for column 0, note the row values – 0, 1, 2 , 3. Remember, the row values correspond to the value in the board array. We are dealing with a row value in column 0 which is the first element in board array, board[0]. This ‘for’ loop is really to determine the row position of the first queen. So this can be translated into code as follows-
for (int i = 0; i < NO_OF_QUEENS; i++) {
board[0] = i; // this will assign the row number
...
}
Dealing with the second Queen
Iteration starting at 0,1 to place second queen
For every position of the first queen, we need to find a position for the second queen. This position will be any one of { 0 , 1 } , { 1 , 1 } , { 2 , 1 } , { 3 , 1 }. We start at {0 , 1 } as shown above. So again, we are looking at a loop which could executes 4 times. Remember, this loop could execute 4 times for each position of queen 1. So we are looking at a nested for loop.
What about the value at index 1 (shown with a ‘ ? ‘ ) in the board array which tracks the position of the 2nd queen ? We do the same thing, start with row 0 and move upto row 3 until we find a correct position. This position will be determined by row and diagonal conflict with queen 1. Let’s go ahead and modify the earlier code to handle this scenario
for (int i = 0; i < NO_OF_QUEENS; i++) {
board[0] = i; // this will assign the row number
for (int j = 0; j < NO_OF_QUEENS; j++) {
board[1] = j;
if (noKill(board, 1)) {
//do something
}
}
}
Line 3 is the nested for loop
Line 4 assigns the current iteration value to the board array element 1.This means it will contain a row value,starting from row 0 and moving on to row 3 until an appropriate position is found. The value at board[1] will represent position of the 2nd queen.
Lines 5,6,7 call the noKill function and pass the board array along with the parameter, 1 , which indicates the current column at which we want to place the 2nd queen. The current column is column number 1
What should happen if noKill returns false ? If it returns false, we found a conflict, it will increment the value of j by 1 and try and find the next position in column 1 for queen 2.
What if it returns true ? If it returns true, it means we found a position for the 2nd queen and we move on to find a position for the 3rd queen. This is really the same procedure as queen 1 and 2. So let’s look at the code for the same.
Dealing with the 3rd and the 4th Queen
for (int i = 0; i < NO_OF_QUEENS; i++) {
board[0] = i; // this will assign the row number
for (int j = 0; j < NO_OF_QUEENS; j++) {
board[1] = j;
if (noKill(board, 1)) {
for (int k = 0; k < NO_OF_QUEENS; k++) {
board[2] = k;
if (noKill(board, 2)) {
for (int l = 0; l < NO_OF_QUEENS; l++) {
board[3] = l;
if (noKill(board, 3)) {
//display queens
}
}
}
}
}
}
}
There are 4 loops, one corresponding to each queen. The final call to the noKill function on line 11 corresponds to column 3, the last column. If we have reached this stage, it means we have found a position for all 4 queens without any conflicts. We can display the positions of the queen by displaying the board array.
Displaying the queens
Displaying the output on a 4 *4 board
We have 2 possibilities of placing the queens without conflicts on a 4 *4 board. We start printing row wise. Every column can have just 1 queen and that is true for the row as well, every row can have 1 queen only. The code displays a ‘Q’ when a row value in the board (accessed by board[j]) array matches the current iteration of the row, otherwise it displays a ‘*’.
Complete code
//Solves 4 queen using nested for loops.
public class FourQueen {
public static int NO_OF_QUEENS = 4;
public static void main(String[] args) {
int [] board = {-1, -1, -1, -1};
for (int i = 0; i < NO_OF_QUEENS; i++) {
board[0] = i;
for (int j = 0; j < NO_OF_QUEENS; j++) {
board[1] = j;
if (noKill(board, 1)) {
for (int k = 0; k < NO_OF_QUEENS; k++) {
board[2] = k;
if (noKill(board, 2)) {
for (int l = 0; l < NO_OF_QUEENS; l++) {
board[3] = l;
if (noKill(board, 3)) {
displayQueens(board);
}
}
}
}
}
}
}
}
private static void displayQueens(int[] board) {
System.out.println("-------------");
int n = board.length;
for (int row = 0; row < n; row++) {
System.out.println("Hello");
for (int value : board) {
if (value == row) {
System.out.print("Q\t");
} else {
System.out.print("*\t");
}
}
System.out.println();
}
}
private static boolean noKill(int[] board, int currentColumnOfQueen) {
for (int i = 0; i < currentColumnOfQueen; i++) {
// same row
if (board[i] == board[currentColumnOfQueen])
return false;
//Diagonal
if ((currentColumnOfQueen - i) == Math.abs(board[currentColumnOfQueen] - board[i])) {
return false;
}
}
return true;
}
}
Conclusion
The code is simple and uses just a single dimension array to store the results. I think it is definitely a good start for understanding the 4 queens problem and the challenges involved in finding conflicts. However the code does not look clean with the 4 nested loops for 4 queens.
This code may be simple but could get ugly if we were to solve 8 queens problem, imagine 8 nested loops and your eyeballs moving from left to right and then from right to left tracking those braces. After this eyeballing, there is a good chance you might want to close your eyes for a few seconds. The good news is that we can get rid of the nested loops using recursion – we seem to be solving the same problem for each column/queen. The single dimension array and the part where we check for conflicts will remain the same and hence this code can be reused to a good extent.
I hope you have understood the challenges and the solution to the 4 queens problem which will definitely give you a strong foundation to tackle the ‘N’ queen puzzle. I think 8 queens or ‘N’ queens using recursion deserves to be a part of another blog.
References
A good description on the google developers guide can be found here .
A great lecture on the MIT OpenCourseWare channel.
In this blog we are going solve an interesting puzzle of bridge crossing in Java. The bridge crossing puzzle is also referred to as the Bridge and Torch problem.We will first understand what the puzzle is all about, come with different logical solutions and finally we will write the code for the same in Java. As always, I will approach the code step by step so that you get a complete understanding of the solution.
What is the bridge crossing problem ?
It is night time and 4 people come to a river. There is a bridge and one torch. They need to get to the other side of the river using the bridge. This bridge is narrow and hence only 2 people can cross the bridge at a time. Since it is night time, the torch has to be used.
Each person takes a certain amount of time to cross the bridge. Person A can cross the bridge in 1 minute, B in 2 minutes, C in 5 minutes and D in 8 minutes. When 2 people cross the bridge, they walk at the slower person’s pace. The question is – Can we get them across the bridge in 15 or fewer minutes since the torch only lasts for 15 minutes ?
A quick solution that comes to mind
If A and B were to start crossing the bridge with the torch, they would take 2 minutes to get to the other side. Person A takes 1 minute and B takes 2 but A has to walk at B’s speed. Person ‘A’ seems to be the fastest among them. So common logic says, let’s get ‘A’ back. So ‘A’ comes back with the torch, now the total time is 3, 2 from earlier one and 1 for ‘A’ to come back. We had 2 journeys so far, 1 forward and 1 backward.
We would assume that since ‘A’ is the fastest, ‘A’ should be the torchbearer and help everyone cross one by one. So ‘A’ and ‘C’ start crossing the bridge. They walk at C’s speed. Now the total time is 3 + 5 = 8. 3 from the earlier journeys and the 5 from C’s speed. Now, our fastest, the torchbearer needs to come back. So 8 + 1 = 9. So we have had 2 more journeys, 4 in all. 2 forward and 2 backward.
Finally, person ‘D’ remains. Our great torchbearer,’A’, and ‘D’ start walking, taking a time of 8 minutes which is D’s speed. The total time is 9 + 8 = 17 minutes. This was one more journey, so we have a total of 4 + 1 = 5 journeys. This was a forward journey. So for 4 people, we had 3 forward and 2 backward journeys and a total time of 17 when A, the fastest among all does the torch bearing activity.
Total time = 17 minutes with 3 forward and 2 backward journeys
Well, well, well – this is not the optimum solution although it seems like it is. The torch only works for 15 minutes !
The right logical solution
It seems that since A takes the least amount of time to cross the bridge, we must send everyone else with A. In the solution above, C and D are crossing separately. If we made them cross together, we could actually do better. Let’s try that solution.
Total time = 15 minutes with 3 forward and 2 backward journeys
This is definitely a better solution and in fact the right solution given the condition. All 4 people have crossed the bridge in 15 minutes. The key here is that in step 3, C and D, the slowest among the 4, travelled together rather than individual trips across the bridge.
Technical analysis
We have 4 people, let us represent this using ‘n’, we have n = 4.
Person
A
B
C
D
timeToCross
[0]
[1]
[2]
[3]
Time taken
1
2
5
8
Time taken by the 4 persons represented using an array, timeToCross
We will be receiving the time taken by each person to cross the bridge as an input. How can we store this ? The simplest is an array. Note that we will sort this array in ascending order.
If we were to sort the array in descending order and started the journey with ‘C’ or ‘D’ , we would have made ‘C’ to travel back with the torch and then ‘C’ has to go to the other side at some point in time. So ‘C’ would have travelled thrice increasing the overall time which would not be a feasible solution.
int [] timeToCross = { 1, 2, 5, 8};
So, timeToCross[0] indicates the time taken by A which is 1 minute. In the logical steps shown above, Step 1 shows ‘A’ and ‘B’ starting off their journey, followed by ‘A’ coming back. How can we represent that using the array we just created ?
Step 1 and 2
timeToCross[1] + timeToCross[0]
Let’s break it up. timeToCross[1] indicates time taken by ‘B’. The first step is ‘A’ and ‘B’ crossing together. The time taken is the time taken by ‘B’ to cross since ‘B’ is slower than ‘A’ and that is the reason why the array is also sorted. So the first logical step of ‘A’ and ‘B’ crossing is represented as timeToCross[1].
The timeToCross[0] is the time taken by ‘A’. Why do we have this ? Well, step 2 is ‘A’ coming back. So we have combined logical steps of 1 and 2 in one line of code.
Step 3
Step 3 is ‘C’ and ‘D’ crossing together. The time taken will be time taken by ‘D’ since ‘D’ is slowest among ‘C’ and ‘D’. How can we represent that using the array?
timeToCross[n-1]
Since, n =4, we refer to it with index, n-1, the index starts from 0. n-1 =3 which is the index of ‘D’.
Step 4
We have managed to get ‘C’ and ‘D’ , the slowest among all 4 to cross the bridge. Now, the next step is ‘B’ coming back with the torch. This can be shown as
timeToCross[1]
At the end of this step 4, we have managed to get 2 people among 4 to the other side of the bridge. What is the total time so far ? Let combine the code from steps 1, 2, 3 and 4.
public static int totalTime(int[] timeToCross , int n)
{
int time = timeToCross[1] + timeToCross[0] + timeToCross[n-1] + timeToCross[1];
}
Extending the problem to have ‘n’ people crossing the bridge
We have 2 people left out of 4. This is 4 -2. We represented this number 4 by ‘n’. If we were to generalize this puzzle for ‘n’ persons, at this point, we would always have ‘n-2’ persons left for crossing. So with ‘A’,’B’,’C’,’D’, we have ‘A’ and ‘B’ left.
What if we have more than 4 persons ? What if we had ‘n’ persons ? We apply the same logic for the remaining n-2 people. It looks like we have solved a part of the problem, a subproblem. When we need to apply the same logic for the remaining data, recursion can be a good idea. The input to this function will be the time that we have calculated so far and the second input will be 2 fewer persons.
public static int totalTime(int[] timeToCross , int n)
{
int time = timeToCross[1] + timeToCross[0] + timeToCross[n-1] + timeToCross[1];
return time + totalTime(timeToCross, n - 2)
}
What if the actual input supplied to this function had only 2 or 3 people instead of 4 ? What if we had just 1 person to cross the bridge ? This can be solved with the following conditions –
public static int totalTime(int[] timeToCross , int n)
{
if (n < 3)
{
//as the elements are sorted.
return timeToCross[n - 1];
}
//3 people will be addition of all.
else if (n == 3)
{
return timeToCross[0] + timeToCross[1] + timeToCross[2];
}
//n>=4
int time = timeToCross[1] + timeToCross[0] + timeToCross[n-1] + timeToCross[1];
return time + totalTime(timeToCross, n - 2)
}
When there are 1 or 2 people to cross the bridge, n = 1 or 2
If the total number of persons who want to cross the bridge is either 1 or 2, we simply return the time taken by n – 1. For 1 person, n = 1 , timeToCross[n-1] will be timeToCross[0] which will be the only input to the problem. For 2 persons, n = 2 , the array is sorted, hence timeToCross[n – 1] = timeToCross[2 -1] = timeToCross[1]. This is the slowest of the 2 persons and the input is also 2 people. The first ‘if’ condition in the code takes care of this scenario.
When there are 3 people to cross the bridge, n =3
If n=3 , time taken will be addition of all 3. How is that ? If A, B and C were to cross the bridge, A and B start the journey, time taken will be the addition of: time taken by ‘B’ , followed by ‘A’ returning with the torch and finally time taken by ‘A’ and ‘C’ which is time taken by ‘C’. So time taken by A +B + C. This is handled with 2nd if condition.
Back to our puzzle where we have 4 people, the final step , step 5
At the end of step 4, C and D are on the other side of the bridge. We are left with A and B. When A and B start crossing the bridge, time taken by them is 2 minutes, since B, the slower one takes 2 minutes. The total time upto step 4 was calculated by code on line 2 below.
//n>=4
int time = timeToCross[1] + timeToCross[0] + timeToCross[n-1] + timeToCross[1];
return time + totalTime(timeToCross, n - 2)
For final step 5, last line above is executed. When called recursively, n < 3, so we return timeToCross[1]. So when ‘A ‘ and ‘B’ are left, timeToCross[1] will be time taken by ‘B’ which is 2. This final step 5 gets handled in the condition: if(n < 3).
public static int totalTime(int[] timeToCross , int n)
{
if (n < 3)
{
//as the elements are sorted.
return timeToCross[n - 1];
}
//3 people will be addition of all.
...
//n >= 4
...
}
Does it work for all scenarios ?
Scenario 2
Person
A
B
C
D
timeToCross
[0]
[1]
[2]
[3]
Time taken
1
2
5
10
4 persons with time as 1, 2, 5, 10
From a logical perspective –
A and B start their journey and take a total time of 2.
‘A’ returns which means the total time is now 2+1 = 3.
‘C’ and ‘D’ walk across, this means, 3 + 10 = 13.
‘B’ returns with the torch, 13 + 2 = 15.
Finally, ‘A’ and ‘B’ walk across, 15 + 2 = 17.
Step 1
Step 2
Step 3
Step 4
Step 5
[A, B] –>
<– [ A ]
[C , D] –>
<– [ B ]
[A , B] –>
2
2 + 1 = 3
3+ 10 = 13
13 + 2 = 15
15 + 2 = 17
4 persons with time as 1,2,5,10
In short, it is {A,B} + {A} + {C,D} + {B} + {A,B}
From the code perspective, n >=4 , so what is executed first is
int time = timeToCross[1] + timeToCross[0] + timeToCross[n-1] + timeToCross[1];
return time + totalTime(timeToCross, n - 2)
timeToCross [] = {1, 2, 5, 10}. So, substituting these values in the code above results in: 2 + 1 + 10 + 2 = 15. See the trace of the logical step above, that is what we get at end of step 4. Finally, the 2nd line in the code snippet above is executed, the recursive call. This will result in 15 + recursive call with n-2.
When this recursive call is executed, n =2. So the first ‘if ‘ condition is satisfied, this returns 15 + timeToCross[n-1] , n = 2, so it returns 15 + timeToCross[1] which is 15 + 2, that is 17. So we get 15 +2 = 17. Looks like the code works fine.
Scenario 3
Person
A
B
C
D
timeToCross
[0]
[1]
[2]
[3]
Time taken
1
20
21
22
4 persons ‘A’, ‘B’ , ‘C’ and ‘D’ with time as 1, 20, 21 , 22 respectively
Well, let us apply the same approach like the earlier scenarios.
A+ B travel together, they take 20 minutes.
‘A’ returns with the torch, 20 + 1 = 21.
‘C’ and ‘D’ travel. This results in a total time of 21 + 22. 21 from earlier one and 22 from current. Total so far is 43.
Now ‘B’ comes back with the torch, 43 + 20 = 63.
Finally, ‘A ‘ and ‘B’ cross, 63 + 20 = 83.
Unfortunately, this is not the optimum solution.
We need another approach here. Let’s try to get C and D to the other end but this time with A, the one taking the least duration to cross.
A + D travel together, time taken is 22.
Then ‘A’ returns, total time is 22 + 1 = 23.
Then ‘A’ and ‘C’ travel. This results in , 23 + 21 , 23 from earlier one and 21 from current. The total so far is 44. Note that, at the end of this step, ‘C’ and ‘D’, the slowest among all are on other side of the bridge.
Now ‘A’ comes back, 44 + 1 = 45.
Finally, ‘A ‘ and ‘B’ cross, 45 + 20 = 65.
Step 1
Step 2
Step 3
Step 4
Step 5
[ A, D ] –>
<– [ A ]
[A , C] –>
<– [ A ]
[A , B] –>
22
22 + 1 = 23
23 + 21 = 44
44 + 1 = 45
45 + 20 = 65
Step by step execution with C and D crossing with A and not together
From the code perspective, we need to make changes to handle this scenario as well. So the sequence here is – {A , D} ,{ A } , {A , C}, {A }, {A , B}. Since, n =4, we get :
The n -1 indicates the index of ‘D’, n -2 indicates index of ‘C’. After this, we have the recursive call which will handle the last part of A+B travelling together.
Two cases for all scenarios
We have seen 2 cases now. How do we choose between them ? Well, we take the minimum from both and solve the subproblem at hand. Then the recursive calls will solve the rest of the problem.
int timeTakenCaseOne = timeToCross[1] + timeToCross[0] + timeToCross[n-1] + timeToCross[1];
int timeTakenCaseTwo = timeToCross[n-1] + timeToCross[0] + timeToCross[n-2] + timeToCross[0];
public static int totalTime(int[] timeToCross , int n){
//Either 2 people or 1 person.
if (n < 3)
{
//as the elements are sorted.
return timeToCross[n - 1];
}
//3 people will be addition of all.
else if (n == 3)
{
return timeToCross[0] + timeToCross[1] + timeToCross[2];
}
// n >= 4
else
{
int timeTakenCaseOne = timeToCross[1] + timeToCross[0] + timeToCross[n-1] + timeToCross[1];
int timeTakenCaseTwo = timeToCross[n-1] + timeToCross[0] + timeToCross[n-2] + timeToCross[0];
if (timeTakenCaseOne < timeTakenCaseTwo)
{
return timeTakenCaseOne + totalTime(timeToCross, n - 2);
}
else if (timeTakenCaseTwo < timeTakenCaseOne)
{
return timeTakenCaseTwo + totalTime(timeToCross, n - 2);
}
return timeTakenCaseTwo + totalTime(timeToCross, n - 2);
}
}
The are no changes in the code when n < 2 or when n = 3. Only changes are when n >= 4. We need to handle 2 scenarios and take the minimum from them. The calculation, timeTakenCaseOne has been calculated like before. timeTakenCaseTwo is the calculation which we had to consider for a scenario that failed. We simply consider the minimum value and recursively solve the subproblem.
Conclusion
We considered multiple scenarios and finally we came up with 2 paths out of which we considered the optimum path. The code can handle all scenarios now and is generic enough for ‘n’ persons wanting to cross the bridge. This was done using recursion which can be a very effective technique to solve problems like the bridge and torch.
The bridge and torch puzzle is an interesting one, the code is really not that difficult but one needs to be aware of all scenarios. As a quick tip, we find optimum time between the 2 cases mentioned below and then apply recursion.
‘C’ and ‘D’ (the slowest) cross together.
‘C’ and ‘D’ (slowest) cross with ‘A’, the fastest among all.
I would request you to solve one scenario on paper to get a much better understanding of the same. A good scenario would be the following input {1,6,10,13,15,16,17}. The output of this should be 75.
Happy bridge crossing !
References
Wiki has a good description about the problem which can help you get started.
A very interesting paper by Rote on this puzzle which does a deep dive.
R-Bloggers has a very good read on the same problem, the code is in R language.