In this post we are going to solve the problem of finding the longest common subsequence. Driven by examples, we will begin by thoroughly understanding the problem and then look at an efficient technique to get to the solution. With this foundation, we will start writing the code in Java.
I have written a detailed blog on finding the longest common substring in Java. That post gives you a step by step explanation about why we chose a 2 dimensional array to represent the two strings, the technique applied to arrive at the solution and a complete walkthrough of the code. We will be using a very similar approach to solve the longest common subsequence problem but there are a few important differences between the two problems. Hence, in this post, we will concentrate mainly on the differences but I will also highlight some of the common points with respect to the solution between these two problems.
What is the meaning of longest common subsequence?
We know that a string is composed of characters. In the longest common substring problem, we need to find the common characters between the two strings but the characters have to be contiguous. In longest common subsequence problem, it is a subsequence, it does not have to be contiguous, that is the main difference! Let’s look at some examples.

As shown above, in the first example, when the input strings are “instagram” and “instantgrammar”, the first string, “instagram” occurs as a subsequence in the second string and it is also the longest among others. In the 2nd example, the longest common subsequence between “facebook” and “brook” is book. Finally, in the 3rd example, it is the complete string,tiktok, appearing as the longest common subsequence in ticktock.
Logical approach – Applying dynamic programming
We applied dynamic programming to solve the longest common substring problem. We will be using the same technique for this problem as well. The key to dynamic programming is –
- Breaking down the main problem into subproblems.
- Solving a subproblem by using the solution from the previous subproblem and then storing the solution to the current subproblem.
If we have two strings and reference the characters at a given index using ‘i’ and ‘j’, we need to find an answer to the question- “What is the longest common subsequence at i , j ? “. In the longest common substring, the answer is- The longest common substring at [ i , j ] is: 1 plus the longest common substring at [ i- 1, j- 1 ] , provided the characters at ‘i’ and ‘j’ are equal. Can we say the same about the longest common subsequence ? Let’s find out.
Finding out the longest common subsequence at a given index
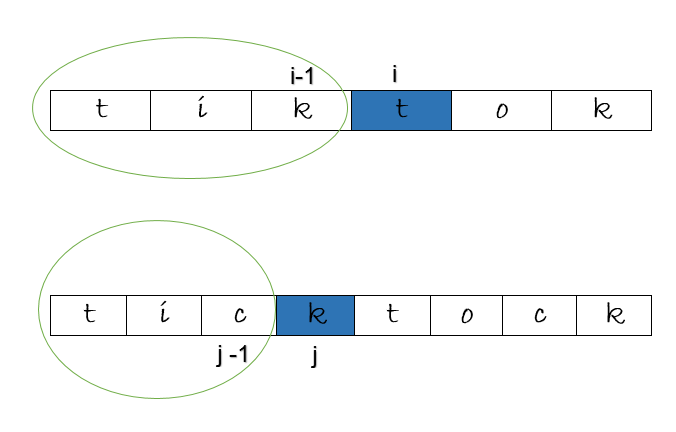
The characters under consideration at i and j as shown above, are ‘t’ and ‘k’ respectively, they are are unequal. Is the length of the longest common subsequence at [ i , j ] equal to the longest common subsequence at [ i – 1, j – 1 ], the previous subproblem ? If this is true, it would give us 2. But, it is not true ! If you look at the input strings, it is 3, the subsequence, “tik”.
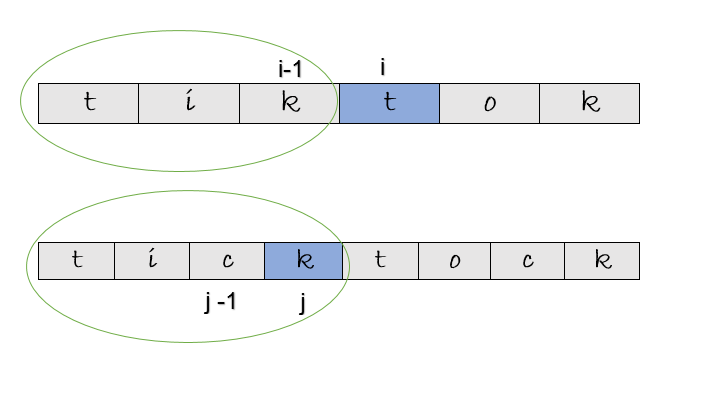
Here, we see that the right answer is [ i -1 , j ]. At this point, “tik” is the longest common subsequence having a length of 3. But, is that check sufficient ? Let’s take a look at another example.

In this example, the characters at [ i , j ] are ‘a’ and ‘b’ respectively, they are not equal. As you can see, the longest common subsequence is not at [ i -1, j -1 ], this will give us 0. Will [ i -1 , j ] give us the right answer ?

Well, in this example, it is not [ i -1 , j ] either. This will give us 0 but the right answer is 1, it is the character ‘a’. How do we get it ?
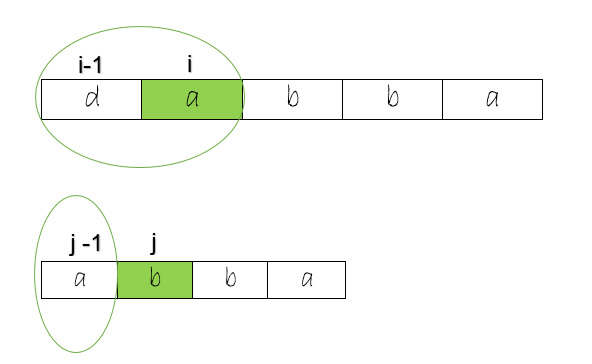
The answer is the longest common subsequence at [ i , j-1 ] as shown above. In one case, when the characters at [i , j] were unequal, the longest common subsequence at [ i , j ] was at [ i -1 , j ] and for another one it was [ i , j – 1 ]. How do we decide which one to take ?
In football, the Golden Shoe award is given to the leading goalscorer in league matches from the top division of every European national league. Similarly, to find the longest common subsequence, we just take the maximum of [ i – 1 , j ] and [ i , j – 1 ]. To conclude, if the characters at [ i , j ] are not equal, the longest common subsequence at [ i , j ] is the maximum of { [ i , j -1 ] , [ i -1 , j] }.
Summary of the logical approach
- If the characters at [ i , j ] are equal, the answer is 1 + the value at [ i – 1 , j -1 ]. This is the same as longest common substring.
- If the characters at [ i , j ] are unequal, the answer is to take the maximum value from: [ i , j -1 ] and [ i -1 , j ].
Let’s take a took at a snapshot of our two dimensional array if we were to apply these 2 steps.
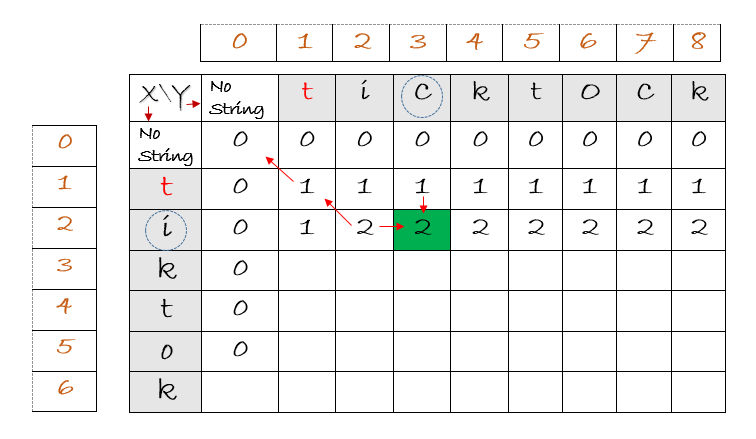
The input strings are tiktok and ticktock. We compared each character in a row against a column in the longest common substring, we will follow the same procedure in longest common subsequence. When the first characters, ‘t’ in these strings are compared, they are equal. Hence, the value is one added to diagonal, which gives 1. Similarly, the comparison between ‘i’ in tiktok and “ticktock”, gives us 2 , one added to diagonal value.
When we compare the character ‘i’ with ‘c’, they are unequal. Here i = 2 and j = 3. So we need to consider : [ i – 1 ] [ j ] = value at [1] [3] = 1 , and [ i ] [ j – 1 ] = value at [2] [2] = 2. The maximum between 1 and 2 is 2. This is indicated with green color above.We apply the same process for the rest of the table. Note that [ i -1] [ j ] indicates the previous row and the same column, and [ i ] [ j -1 ] is same row but previous column.

The table above shows you the result at the end of the procedure. As we can see, the length is 6, it is the length of the string, “tiktok”, which is the common subsequence between the two strings.
Breaking down the code
Logic for the comparisons
The code for creating and initializing the 2-d table remains the same as the code for finding the longest common substring. The major change involved is in the step when the characters under comparison are different.
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (x.charAt(i - 1) == y.charAt(j - 1)) {
lcsTable[i][j] = 1 + lcsTable[i - 1][j - 1];
if (maxLength < lcsTable[i][j]) {
maxLength = lcsTable[i][j];
maxRow = i;
maxColumn = j;
}
} else {
lcsTable[i][j] = Math.max(lcsTable[i - 1][j], lcsTable[i][j - 1]);
}
}
}
If the characters at an index [i , j ] are not equal, the code on line 11 takes care of finding the maximum of 2 values. If you need an in depth explanation of of the other lines in the code, please refer to my earlier post on finding the longest common substring. The code above will fill up the table with appropriate values.
Retrieving the longest common subsequence
Now that we have our table ready, it’s time to get the actual common subsequence with the longest length. The maxLength, maxRow and maxColumn values are maintained for the same purpose. The values in maxRow and maxColumn reflect the cell where the maximum length was found.
To get the actual subsequence,we travel backwards with the same logic we travelled forward. If the characters at a particular index [ i , j ] or [row, column] are equal, we take that character and move backwards to the diagonal. If they are unequal, we decide the maximum between [ i – 1 , j ] and [ i , j – 1 ]. If [ i -1 ] [j] is greater, we go to the previous row else to the previous column. This is simply a reduction in index value of either i or j.

To help you to trace backwards, start at [ 6, 8] which shows a maximum length of 6. Notice the row and column number along with the character. If they are all in same color, it’s a match and we go to the diagonal. Now, we are at cell [ 5, 7 ]. The previous row is [4 , 7] and previous column is [5 , 6 ], see the length shown in circles ( full and dotted). We take the maximum value(full circle) and decrement either the row number or column number by 1.(In his case it is the column number). This is just the exact opposite of how we filled the value at cell, [ 5 , 7 ]. The code for this track back is-
StringBuilder longestSubsequence = new StringBuilder();
while (maxRow >= 1 && maxColumn >= 1) {
if (x.charAt(maxRow - 1) == y.charAt(maxColumn - 1)) {
longestSubsequence.append(x.charAt(maxRow - 1));
maxRow--;
maxColumn--;
} else {
if (lcsTable[maxRow - 1][maxColumn] >= lcsTable[maxRow][maxColumn - 1]) {
maxRow--;
} else {
maxColumn--;
}
}
}
Complete code
package ds;
public class LongestCommonSubsequence {
private static String findLongestCommonSubsequence(String x, String y) {
int m = x.length();
int n = y.length();
int[][] lcsTable = new int[m + 1][n + 1];
int maxLength = 0;
int maxRow = 0;
int maxColumn = 0;
// init first row with 0
for (int i = 0; i < m; i++) {
lcsTable[i][0] = 0;
}
// init first col with 0
for (int j = 0; j < n; j++) {
lcsTable[0][j] = 0;
}
// starting from 1 as row 0 and col 0 filled with 0. <= since it has go up to
// string length.
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (x.charAt(i - 1) == y.charAt(j - 1)) {
lcsTable[i][j] = 1 + lcsTable[i - 1][j - 1];
if (maxLength < lcsTable[i][j]) {
maxLength = lcsTable[i][j];
maxRow = i;
maxColumn = j;
}
} else {
lcsTable[i][j] = Math.max(lcsTable[i - 1][j], lcsTable[i][j - 1]);
}
}
}
StringBuilder longestSubsequence = new StringBuilder();
//Remember that row 0 and column 0 indicate absence of one of the strings.
while (maxRow >= 1 && maxColumn >= 1) {
if (x.charAt(maxRow - 1) == y.charAt(maxColumn - 1)) {
longestSubsequence.append(x.charAt(maxRow - 1));
maxRow--;
maxColumn--;
} else {
if (lcsTable[maxRow - 1][maxColumn] >= lcsTable[maxRow][maxColumn - 1]) {
maxRow--;
} else {
maxColumn--;
}
}
}
return longestSubsequence.reverse().toString();
}
public static void main(String[] args) {
String a = "tiktok";
String b = "ticktock";
String longestCommonSubsequence = findLongestCommonSubsequence(a, b);
System.out.println("The longest common subsequence is " + longestCommonSubsequence);
}
}
Since we are tracking backwards now, notice that on line 58, we reverse the string.
Conclusion
Using the technique of dynamic programming, we were able to find a solution to this problem. A 2 dimensional array was sufficient to store the length found at every position in the two strings. By addressing a subproblem and storing the results in a table, we were able to determine the result for the next subproblem. The time complexity of finding the length of the longest common subsequence is O(m * n) where ‘m’ and ‘n’ are the lengths of the two strings.
The code for the longest common subsequence and longest common substring have a lot in common but I decided to keep them in separate blogs. I did not want to put everything into one post, I personally think keeping it separate will help you understand both better.Understanding longest common substring first followed by subsequence is a good idea.
