In this blog I am going to give you a detailed understanding of how to find if two strings are anagrams of each other. We will first understand what an anagram is, consider different types of input data and then finally move on to write the code in Java. Like always, we will approach this step by step. Along the way, I will deliberately make a few mistakes which will result in incorrect results for a few cases. We will then fix the code so that we get the appropriate results for all inputs. This way, you will understand the code a lot better.
What is an anagram ?
An anagram is a word or a phrase formed by rearranging the letters of another word or phrase. This is straight out of wiki. I think it is a good read if you are interested in the history of anagrams and the application of anagrams.
Let us break the definition down into 2 parts –
- ‘An anagram is a word or a phrase’ – The phrase part is important as most examples focus on just a single word.
- ‘formed by rearranging the letters of another word or phrase’ – This is straightforward to understand – the key here is rearrangement.
Examples of Anagrams
- “evil” = “vile” – Of course they don’t mean the same ! These are anagrams since the frequency of each character is the same in both words. It is just rearranging the characters in the word ‘evil’, which gives us the word vile.
- “coronavirus” = “carnivorous” – same frequency of each character in the words coronavirus and carnivorous and just rearrangement of characters.
- “debit card” = “bad credit”. This is a different kind of an example – a phrase ! Note that this has a space in between, make a note of this. The characters in the phrase on the left side have same frequency of characters as on the right side.
- “William Shakespeare” = “I am a weakish speller”. A couple of different things to notice in this example – The name on the left side is in uppercase but the one on right side is in lowercase. Another observation is that the name has changed into a sentence. The frequency of the characters on the left side is still the same as on the right side, just rearrangement as usual.
Common observations
For 2 words or phrases to be anagrams –
- The 2 words/phrases must have same characters along with same frequency.
- They can have a space in between which we need to handle.
- Upper/Lower case of the words/phrases should be handled appropriately.
Time for some code
We need to check if 2 strings/phrases are anagrams. Hence, the input will be 2 strings. Let’s assume that they are not null. If they are anagrams, we return a true else return false. This can easily be translated into a function in Java which takes 2 parameters and returns a boolean value. Let’s call that function, isAnagram.
public static boolean isAnagram(String first, String second) {
return true;
}
The function, isAnagram, takes 2 parameters and returns true for the moment.
Let’s consider our first example of “evil” and “vile”. These are anagrams. The characters have been rearranged. What if we were to arrange them in the same way ?
To arrange the characters in the same way, we need the characters from the string. A string is made up of characters. We can use the toCharArray function on a string to get each character.
char[] charactersOfFirst = first.toCharArray();
char[] charactersOfSecond = second.toCharArray();
We have our character array from each string. How do we arrange them in the same way ? Well, we can sort the characters in each array using the Arrays class.
Arrays.sort(charactersOfFirst);
Arrays.sort(charactersOfSecond);
What is left now is simply checking if the sorted characters are the same. How do we do that ? We can use the Arrays. equals method for this and pass the sorted character arrays to it.
return Arrays.equals(charactersOfFirst, charactersOfSecond);
Combining the code from last 3 steps
public static boolean isAnagram(String first, String second) {
char[] charactersOfFirst = first.toCharArray();
char[] charactersOfSecond = second.toCharArray();
Arrays.sort(charactersOfFirst);
Arrays.sort(charactersOfSecond);
return Arrays.equals(charactersOfFirst, charactersOfSecond);
}
Well, that’s it ! Passing the inputs as “evil” and “vile” gives us true. Passing inputs as “coronavirus” and “carnivorous” also give us true.
Pictorial view of code execution when input is “evil” and “vile”

Does this code work for all cases ?
If we were to pass the inputs as “customers”and “store scum”, the function returns false. It should have returned true. The characters are the same along with the frequency. However, did you notice that there is a space in the second word , store scum?

Do you remember that this was one of the scenario we were going to handle ? Well, now is the right time to handle it ! This is simple – just replace the space between the words with an empty string. How do we do that in Java? Use the replaceAll method from String class.The replaceAll method takes 2 parameters, a regular expression in String format and the replacement String. The regular expression for space is: “\s” and we need to replace it with “”, an empty string. So with this understanding, our modified code will be –
public static boolean isAnagram(String first, String second) {
char[] charactersOfFirst = first.replaceAll("\\s", "").toCharArray();
char[] charactersOfSecond = second.replaceAll("\\s", "").toCharArray();
Arrays.sort(charactersOfFirst);
Arrays.sort(charactersOfSecond);
return Arrays.equals(charactersOfFirst, charactersOfSecond);
}
You can see the highlighted code for the changes. The extra ‘\’ in “\\s” is to escape the ‘\’ in the string “\s”. With this change, we get the correct output of true when the input is “customers” and “store scum”. If we were to pass the input as “debit card” and “bad credit”, we get true.
Are we done now ? Well, not really. If we were to pass the input as “William Shakespeare” and “I am a weakish speller”, we get false, which is the incorrect answer. The frequency of the characters is the same in both strings, we handled the space as well.
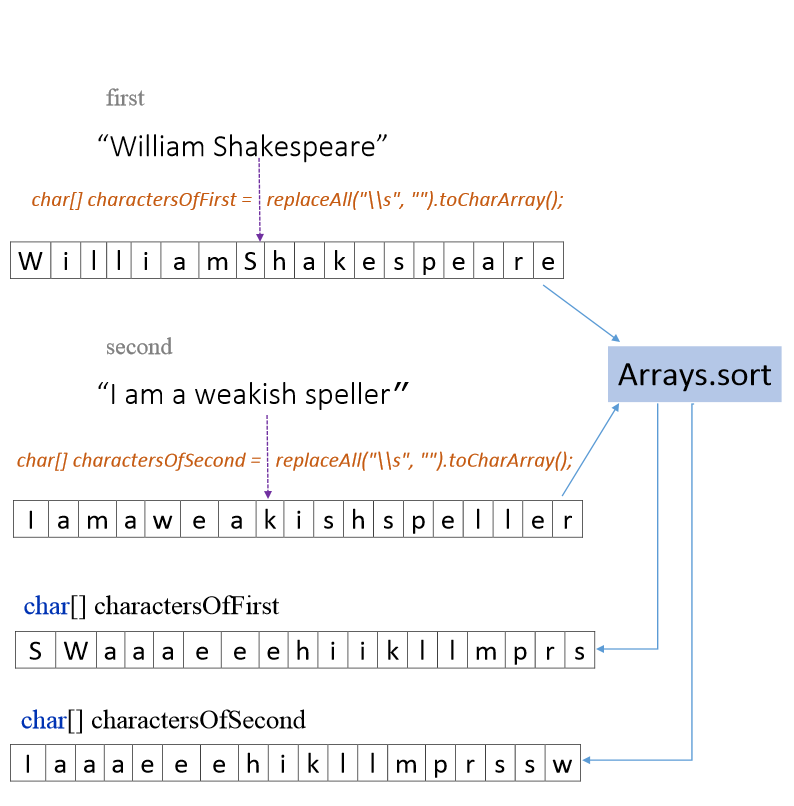
Why is it failing ? Did you notice that the characters ‘W’ and ‘S’ in the first input string are in capital letters but in the second string, they are in lower case. The character arrays are sorted based on the ascii codes for upper and lower case letters. Ascii code for upper case letters starting from ‘A’ begins from 65 and for ‘a’, it starts from 97. So sorting them with mixed case characters and then applying equals does not help. The Arrays.sort method sorts each character array in ascending format. So in each character array, you see upper case letters(lower ascii) first followed by lower case(higher ascii value). Let’s modify the code to handle this scenario.
public static boolean isAnagram(String first, String second) {
char[] charactersOfFirst = first.replaceAll("\\s", "").toLowerCase().toCharArray();
char[] charactersOfSecond = second.replaceAll("\\s", "").toLowerCase().toCharArray();
Arrays.sort(charactersOfFirst);
Arrays.sort(charactersOfSecond);
return Arrays.equals(charactersOfFirst, charactersOfSecond);
}
As shown in the highlighted code above, we only add the call to the function toLowerCase(). We add this function call for both the inputs. By doing this, we treat characters in both inputs as lower case. Now, if were were to pass the input as “William Shakespeare” and “I am a weakish speller”, we get true, which is the correct input.
I know what you are thinking now. You must be saying , “Oh, please tell me that we are done now ! “. Well, just one more change and our code will be ready for all scenarios. In fact I would say the next change is more of an improvement.
Final changes to the code
We have handled spaces, case sensitivity and the contents of the string by converting it to a character array and then sorting it. But what if the input strings are of unequal length even after removing the spaces ? In this scenario, we don’t want to sort the array and compare them later. What we can do is simply check for the length of the 2 character arrays after we remove the spaces between the words.
public static boolean isAnagram(String first, String second) {
char[] charactersOfFirst = first.replaceAll("\\s", "").toLowerCase().toCharArray();
char[] charactersOfSecond = second.replaceAll("\\s", "").toLowerCase().toCharArray();
if (charactersOfFirst.length != charactersOfSecond.length) {
return false;
}
Arrays.sort(charactersOfFirst);
Arrays.sort(charactersOfSecond);
return Arrays.equals(charactersOfFirst, charactersOfSecond);
}
It would be incorrect to check for length of the input strings as the first step in the function. If the input strings were “William Shakespeare” and “I am a weakish speller” and we were to check for the length of the string before converting it into a character array, the code would return false. The length of the string “William Shakespeare” is 19 and length of “I am a weakish speller” is 22. Even though they are valid anagrams, comparing input string lengths would not be right.
Conclusion
We have handled most of the scenarios and I think the code above is the final version. But it is the final version using this approach of sorting the character array and using the Arrays.equals method to check for contents. This is not just a valid solution but a good solution as well. I have not considered a scenario where the string contains special characters but this can be handled in the same way we handled the spaces.
The code above which uses sorting has time complexity of O(n log n). We can improve this code further by using a different technique where we can avoid the sorting. I will definitely write another blog on this soon. Until then, Happy Anagramming !