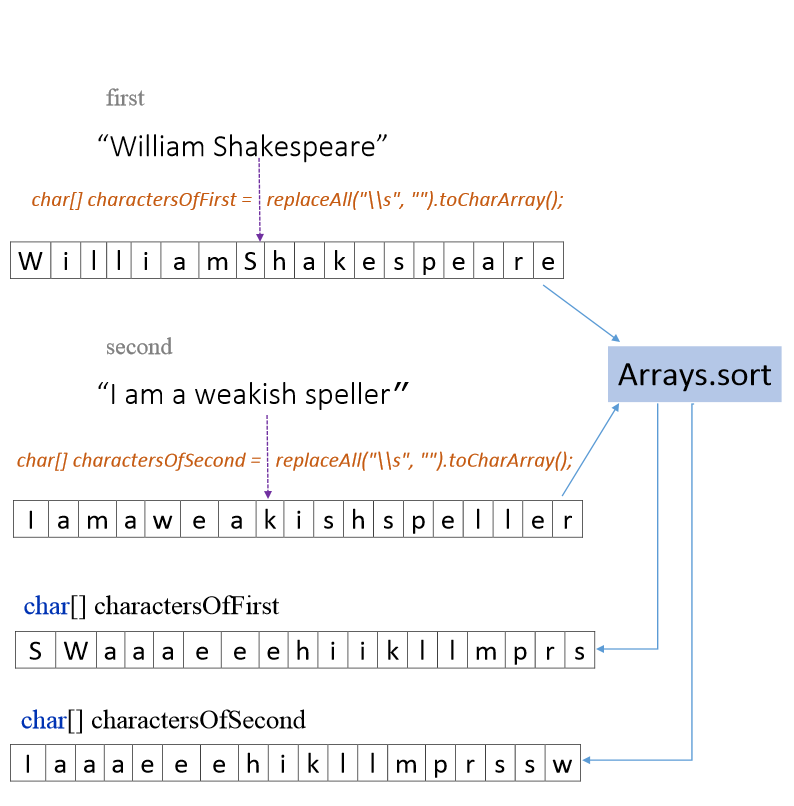
In this blog we are going to learn how to find if 2 given strings are anagrams of each other. We will be solving this problem without sorting the 2 strings and see if we can improve on the time complexity. I have a step by step explanation of finding if 2 strings are anagrams using a sorting technique here. If you are completely new to anagrams and would like know about solving this in Java using sorting, I would urge you read that first.
How can we solve this problem without sorting the strings ?
Let’s start with a simple example, an example which we saw in the previous blog about anagrams – “evil” and “vile” or “coronavirus” and “carnivorous”. These are anagrams since the characters in them are the same and they appear the same number of times, the characters are just rearranged.
They key here is that they appear the same number of times. This means the frequency of each character in the 2 strings is the same. In the string “evil”, each character, ‘e’, ‘v’, ‘i’ and ‘l’ appears once in the string “vile”.
The image below shows you the frequency of each character in the strings “coronavirus” and “carnivorous”

It is clear that each character in “coronavirus” has same frequency as characters in “carnivorous”. Can we use this frequency to figure out if they are anagrams ?
Finding out the frequency of each character in the string
Like the previous blog, we are going to remove any spaces and also going to convert all letters to lowercase. So let’s begin with some code.
public static boolean isAnagram(String first, String second) {
char[] charactersOfFirst = first.replaceAll("\\s", "").toLowerCase().toCharArray();
char[] charactersOfSecond = second.replaceAll("\\s", "").toLowerCase().toCharArray();
if (charactersOfFirst.length != charactersOfSecond.length) {
return false;
}
//Code here for frequency check.
return true;
}
We have converted both strings into character arrays like we did in the version of the code which used sorting.
How do you usually check the frequency of any object ? If I were to give you a bag full of toys and asked you to tell me the type and the number of each type of toy, you would probably say – “There are 3 planes, 2 tennis balls and 1 football.” What did you just do ? We grouped each type of toy and starting counting them. You must be saying to yourself, “Why did he come up with an example of counting toys !”. Well, with a lockdown, with kids home and the ever increasing list of things to do, you better know everything about all the toys at home !
With strings, which are composed of characters, we need to count each type of character. You can imagine a string as a bag full of characters. In the toy example, we had only 3 items. It’s easy to remember 3 items and the count of each one of them. What if the bag had 15 items ? Would you be able to remember that along with the number of each type ? You would probably make a note of it and have 2 columns, toy type and count. In case of characters, we need to find out the type of character(letter) and the count of each character. So, we need 2 things, character type and count of each type. How many lower case letters can there be ? Well, 26. You wouldn’t make 26 variables now. How can we emulate a note like structure ? Well, an array can help us here. What should be the size of the array? 26, for 26 letters, ‘a’ – ‘z’.
int[] frequencies = new int[26];
How do we maintain the count against each character ?
We have defined an array of size 26 to store the count of each character from ‘a to ‘z’. But how do we increase of count of ‘c’ if we get multiple ‘c’ ? Every letter has an Ascii code. For the letter ‘a’, it is 97, ‘b’ is 98 and so on. What if we could store the count of the character ‘a’ at index 0, ‘b’ at index 1 and so on? Well if the character in the string is an ‘a’ and we subtract an ‘a’ from it, we are actually saying ‘a’ –‘a’ or 97 – 97 which is 0. This can be used as an index into the frequency array which we defined above. If we get a ‘b’, we find the index of ‘b’ as ‘b’ – ‘a’ which is 98 – 97 = 1. So we access index 1 in the array. We do the same for every character we encounter in the string.
Now, we need to store the value at each index – the value will be the count of each character. The values in the array will be initialized to 0. Each time we encounter a character, we access the array at the correct index and simply increment the value.
Let’s take an example of 2 strings, “abby” and “baby”.

As shown above, the index of ‘a’ is 0, ‘b’ is 1 and so on. When we start visiting each character in the string “abby”, we perform a ‘character’ -‘a’ and simply increment the counter at that index. The value at index 1 is 2, this shows that ‘b’ occurs twice. The characters ‘a’ and ‘y’ appear only once. Using this logic, we have maintained the count of each character in the frequency array.
for (int i = 0; i < charactersOfFirst.length; i++) {
frequencies[charactersOfFirst[i] - 'a']++;
}
What about frequency of the characters in the second string, “baby” ?
We could create another array and store the frequency of the characters in that 2nd array. Once we create that 2nd array, the 2nd array would have same values for the string “baby” since ‘b’ occurs twice and the characters ‘a’ and ‘y’ appear once. We could then iterate through arrays and compare the value at each index. If a value at an index is different, they are not anagrams.
Do we need a second array ? Can we use the same array for the 2nd string as well ? What we could do is simply decrement the count in the frequency array for each character that occurs in the 2nd string. So for the 2nd string, if we encounter an ‘a’, we go to the index of ‘a’, which is 0 and decrement the value at that index. This will make it 0 for the current example.
frequencies[charactersOfSecond[i] - 'a']--;
How does this help ? Well, if the frequency of the characters in the 2 strings are the same, the first increments it and the 2nd decrements it and at the end of it, all values in the array should be zero.

As shown in the figure above, when we iterate through the first string, we increment the count as shown in top half. In the bottom half, we decrement the values in the same array. The final values can be seen in the middle. In this case, since “abby” and “baby” have same frequency of characters, the entire array has value 0.
Combining all these changes in the code
public static boolean isAnagram(String first, String second) {
char[] charactersOfFirst = first.replaceAll("\\s", "").toLowerCase().toCharArray();
char[] charactersOfSecond = second.replaceAll("\\s", "").toLowerCase().toCharArray();
if (charactersOfFirst.length != charactersOfSecond.length) {
return false;
}
int[] frequencies = new int[26];
for (int i = 0; i < charactersOfFirst.length; i++) {
frequencies[charactersOfFirst[i] - 'a']++;
frequencies[charactersOfSecond[i] - 'a']--;
}
for (int frequency : frequencies) {
if (frequency != 0) return false;
}
return true;
}
The 2nd for loop checks if any value in the frequency array is not equal to 0. A value other than 0 would indicate that either there is a different character or frequency of the characters do not match. A positive value would indicate a character in the first string that does not appear in the second and a negative one means the character appears in the 2nd string and not in the first.
Conclusion
Using a single array and the ascii code of the letter to count the frequency of the characters is a simple but effective approach to check if 2 strings are anagrams. In fact, this solution has a time complexity of O(n). We did reserve an array of size 26 but that is not much of a concern since we don’t resize the array. We could have avoided the use of the character array and used another string after removing the spaces and converting the string to lower case but I will leave that as an exercise for you. Happy anagramming !