In this article we will be taking a look at switch expressions that have been incorporated in JDK 14 which was released on 17th March 2020.Switch expressions were made available as a preview language feature in JDK 12 and 13. Based on the feedback, changes were made and now this feature has been finalized in JDK 14.Let us start with a simple example of a switch block:
public int getNumberOfRooms(int budget) {
int numberOfRooms = 0;
switch (budget) {
case 1000000:
numberOfRooms = 1;
break;
case 2000000:
case 3000000:
numberOfRooms = 2;
break;
case 4000000:
case 5000000:
numberOfRooms = 3;
break;
default:
System.out.println("Hello");
}
return numberOfRooms;
}
Vintage switch
The method above takes in a budget as parameter and depending on the budget it returns the number of rooms that one can buy with the budget. For simplicity, let us assume that we have a flat budget. 1 million can get us a single room. 2 and 3 million can get us 2 rooms and finally 4 and 5 million can get us 3 rooms.
Some observations about the usage of switch statement in the example above:
- Most usage of switch statements do some processing and return a value.
- Most case blocks have a break statement to avoid fall through otherwise it will execute the next case block till it encounters a break – it is quite easy to forget a break and well, adding a break serves the purpose but can make the code difficult to read at times. As experienced Java programmers, we are now used to it.
- The default case is optional and it does not enforce the programmer to throw an exception or return a value. I could add a System.out.println there and the code will compile and run.
- Multiple cases which require common logic to be processed have separate case labels on different lines with no break in between them which takes an effort to read and understand – Again we are used to it but imagine folks being introduced to the language for the first time.
The new modern switch
public int getNumberOfRooms(int budget) {
int numberOfRooms = switch (budget) {
case 1000000 -> 1;
case 2000000, 3000000 -> 2;
case 4000000, 5000000 -> 3;
default -> throw new IllegalStateException("No rooms available for this budget");
};
return numberOfRooms;
}
- The new switch assigns/returns a value to a variable on the left side, hence called switch expression. Notice the semicolon on line 8 at the end of the switch block.
- Multiple cases are combined on the same line with a comma.
- The right hand side is separated with arrow (->) instead of a colon.
- No break in between cases, there is no fall through by default.
- The default case has to either return a value or throw an exception.
- Last but not the least and in fact an important difference is that this code is definitely more pleasing to the the eye and easier to understand.
Yield and scope in the modern switch
Let us introduce a small change in the business requirement. If we have a budget of 3 million or 5 million we need to give the customer a discount.Doing this using the vintage switch would lead to the following code:
public int getNumberOfRooms(int budget) {
int numberOfRooms = 0;
switch (budget) {
case 1000000:
numberOfRooms = 1;
break;
case 2000000:
case 3000000:
int finalPrice = (budget == 3000000) ? budget - 100000 : budget;
System.out.println("Final price after discount " + finalPrice);
numberOfRooms = 2;
break;
case 4000000:
case 5000000:
int finalPriceThreeRooms = (budget == 5000000) ? budget - 100000 : budget;
System.out.println("Final price after discount " + finalPriceThreeRooms);
numberOfRooms = 3;
break;
default:
throw new IllegalStateException("No rooms available for this budget");
}
return numberOfRooms;
}
If you see line number 9 and line number 15 , we introduced 2 variables which does the same thing but we had to give it different names. This is because any variable introduced in case block stretches for the entire switch block.
Let us implement this using modern switch construct
public int getNumberOfRooms(int budget) {
int numberOfRooms = switch (budget) {
case 1000000 -> 1;
case 2000000, 3000000 -> {
int finalPrice = (budget == 3000000) ? budget - 100000 : budget);
System.out.println("Final price after discount " + finalPrice);
yield 2;
}
case 4000000, 5000000 -> {
int finalPrice = (budget == 5000000) ? budget - 100000 : budget;
System.out.println("Final price after discount " + finalPrice);
yield 3;
}
default -> throw new IllegalStateException("Unexpected value: " + budget);
};
return numberOfRooms;
}
Using the modern switch, if a case block has multiple lines, we make use of a yield statement which indicates that the case block yields a value. Besides this, another salient feature is that the finalPrice variable introduced inside the case block remains local to that block which makes reading and understanding code easier. I have seen lots of code where variables are named using weird combinations like temp1, temp2, temp3 or finalPrice1,finalPrice2,finalPrice3 …This change does not enforce you to give meaningful names to variables but signals a clear intention about the scope of a variable in the case block.
More on the yield statement
The yield statement was introduced after seeking feedback. In JDK 12, break statement was used in switch expression which was confusing. It was hence decided to introduce the yield statement in switch expressions. I have been calling the switch in versions of JDK prior to 12 as vintage but they continue to exist along with the modern switch.
Some nuances with mixing and matching
- We cannot use the arrow and the colon in the same switch block. We get a compile time error “Different case kinds used in switch”
public int getNumberOfRooms(int budget) {
int numberOfRooms = 0 ;
switch (budget) {
case 1000000 : numberOfRooms = 1;
case 2000000,3000000 -> {
…
}
case 4000000, 5000000 -> {
…
}
default -> throw new IllegalStateException("Unexpected value: " + budget);
};
return numberOfRooms;
}
- In case of the switch statement, we can use the new case label using the arrow. Doing this means there is no fall through and multiple cases can be combined using comma. You can add a break statement( no compiler error) but the arrow case label means there is no fall through
public int getNumberOfRooms(int budget) {
int numberOfRooms;
switch (budget) {
case 1000000 -> {
numberOfRooms = 1;
}
case 2000000, 3000000 -> {
int finalPrice = (budget == 3000000) ? budget - 100000 : budget;
System.out.println("Final price after discount " + finalPrice);
numberOfRooms = 2;
//redundant because of arrow.
break;
}
case 4000000, 5000000 -> {
int finalPrice = (budget == 5000000) ? budget - 100000 : budget;
System.out.println("Final price after discount " + finalPrice);
numberOfRooms = 3;
}
default -> throw new IllegalStateException("Unexpected value: " + budget);
}
return numberOfRooms;
}
- In case of a switch expression, we can use the old vintage style of using a colon for the case blocks. But since this is an expression, each case block must return a value using yield.
public int getNumberOfRooms(int budget) {
int numberOfRooms = switch (budget) {
case 1000000: {
yield 1;
}
case 2000000, 3000000: {
int finalPrice = (budget == 3000000) ? budget - 100000 : budget;
System.out.println("Final price after discount " + finalPrice);
yield 2;
}
case 4000000, 5000000: {
int finalPrice = (budget == 5000000) ? budget - 100000 : budget;
System.out.println("Final price after discount " + finalPrice);
yield 3;
}
default:
throw new IllegalStateException("Unexpected value: " + budget);
};
return numberOfRooms;
}
Conclusion
The new switch expression feature will make our code more readable, intuitive and less error prone. This feature acts as a foundation for more changes to come in the Java language, one of them is pattern matching.









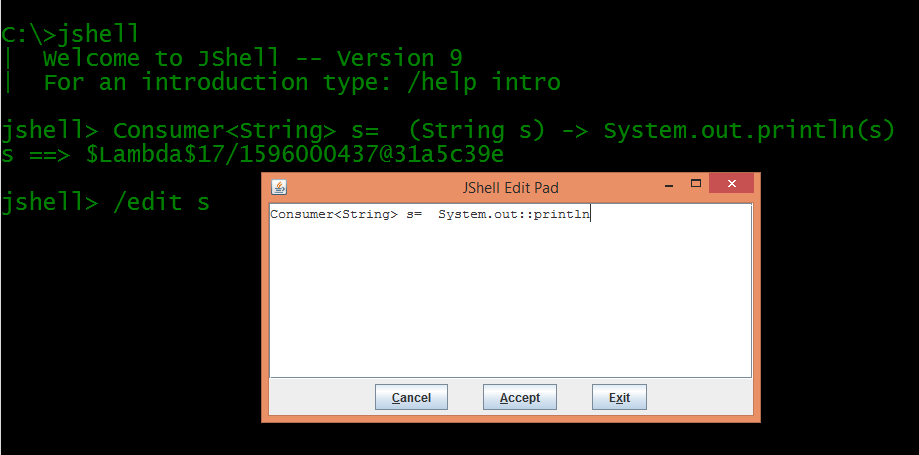
 Typing the /edit command as shown above opens up a window where you can go and edit the code you typed. Using our knowledge of method reference, we can change the lambda expression from (String s) -> System.out.println(s) to System.out::println. On clicking the accept button, the change is reflected.
Typing the /edit command as shown above opens up a window where you can go and edit the code you typed. Using our knowledge of method reference, we can change the lambda expression from (String s) -> System.out.println(s) to System.out::println. On clicking the accept button, the change is reflected.